





Článek
Když mladý vývojář ze Šumperka v roce 2012 nastoupil do Googlu, měl už za sebou prestižní stáž na americké univerzitě i zkušenost z výzkumného týmu Microsoft Research. Dlouhodobě se chtěl Tomáš Mikolov věnovat zlepšování strojových překladů. Napřed se však rozhodl dokončit menší projekt, aby před svými novými kolegy „ukázal, že ví, o čem mluví“.
Na konci tohoto „projektíku“ stála jedna z nejcitovanějších studií v oboru informatiky vůbec. A také dnes již legendární nástroj word2vec, který může kdokoli použít k překvapivě účinné analýze textu. Poté navázal výzkumem ve Facebooku, a na světě byl další masivně populární nástroj k volnému použití.
Navzdory svým úspěchům, nebo možná díky nim, Mikolov nedávno přerušil svou šňůru po velkých technických firmách v USA. Vrátil se do Česka, aby vedl svůj vlastní výzkumný tým. Velké firmy podle něj kazí debatu tím, že schválně nafukují schopnosti tzv. AI. Ostatně už jen samotný pojem artificial intelligence (umělá inteligence) je dost zavádějící…
Pozor na nafouknuté sliby
Významně jste se zasloužil o rozvoj strojového učení, teoreticky i prakticky. Z vašich veřejných vystoupení mám ale pocit, že se snažíte spíše krotit nekritické nadšení.
Nechci nabourávat ten optimismus, to rozhodně ne. Ale mám dojem, že se o umělé inteligenci dnes mluví až moc. Často je to součást různých byznys plánů. Vyjadřuje se k tomu skoro každý. Přitom to, co se dnes v korporacích vydává za umělou inteligenci, je obvykle strojové učení. A to je vlastně taková nafouknutá statistika.
Ta část strojového učení, která začala zrovna fungovat hodně dobře, to jsou neuronové sítě. Což je zase zavádějící název, evokuje to nějakou snahu o napodobení lidského mozku. Tak to možná bylo kdysi na počátku, ale dnes už jsou umělé neuronové sítě matematické modely, v podstatě lineární algebra, nemá to nic společného s lidským mozkem. Když někdo mluví o „simulaci mozku“, tak tomu buď nerozumí nebo je to podvodník.
Strojové učení a neuronové sítě
Strojové učení funguje na principu analýzy velkého množství dat. Počítačové programy jsou sadou instrukcí a podle těchto instrukcí zpracovávají předložená data. Strojové učení umožňuje nový přístup k řešení problémů počítačem. Než aby programátor počítači napsal veškeré instrukce pro všechny eventuality jednotlivě, tak naprogramuje způsob, kterým se počítač sám učí na dodaných „trénovacích“ datech. Učení probíhá pomocí sítí samostatných programů, tzv. umělých neuronů, proto se systému říká neuronová síť.
Například v případě strojového překladu se počítač trénuje na velkém množství textů, které jsou dostupné v angličtině i češtině. Neuronová síť zkouší překládat části textu a poté zkontroluje, nakolik se její verze liší od té správné. Ty části neuronů, jež napovídaly správnou možnost, budou posíleny a příště budou hrát v rozhodování větší roli. Čím rozsáhlejší a kvalitnější jsou vstupní data, tím lepší může být výsledek.
Lidé mohou získat z těch marketingových řečí dojem, že je uvnitř počítače nějaká inteligence podobná té lidské. Myslím, že lidé by měli od nálepky „umělá inteligence“ očekávat spíše pokročilé počítačové programy. S „inteligencí“ to zatím nemá moc společného. Jsou to velké statistické modely, které mohou zpřístupnit nové, dříve nerealizovatelné funkce.
Čím byste lidem ukázal slabiny strojového učení?
Vědci se někdy chlubí úžasnými výsledky. Třeba že jejich neuronová síť dokáže na obrázku identifikovat zvíře s 90% úspěšností, nebo dokonce s větší úspěšností než lidé. Jenže se ukázalo, že tyto úspěšné sítě lze snadno oklamat. Pomocí cílené, ale člověkem naprosto nepostřehnutelné úpravy snímku lze neuronovou síť přesvědčit, že na fotce není pes, ale třeba žirafa nebo autobus.
Změnou jediného pixelu výzkumníci dokázali ošálit oblíbené klasifikátory založené na principech strojového učení. Auto pak umělá inteligence označí za letadlo, jelena za psa, kočku za ptáka apod.
Musíme si zkrátka uvědomit, že počítač nevnímá obrázek tak, jako jej vidíme my. Detekuje tam nějaké vzory, které se v trénovacích datech často objevovaly společně s nějakou přiřazenou třídou. Když začnete pak náhle používat jiná data, třeba obrázky nafocené za jiných světelných podmínek, tak úspěšnost může být najednou katastroficky nízká.
Takových příkladů je celá řada. Já dělal doktorát v oblasti rozpoznávání řeči. Když natrénujeme počítač na vzorcích čtené řeči, kde mluvčí jasně vyslovuje, tak takto naučený model naprosto selhává na zašuměných nahrávkách z auta. Schopnost generalizace modelů na měnící se podmínky je mnohem nižší, než by člověk čekal. Což se tedy někdy maskuje tím, že se použijí obrovská kvanta trénovacích dat, třeba obrázky zvířat ze všech možných úhlů a se všemožnými světelnými podmínkami.
Z čeho ta přehnaná očekávání pramení?
On je totiž problém, že i řada lidí z naší komunity vědců a vývojářů často ty výsledky přehání. Říkají taková tvrzení, jako že počítač lépe rozpozná obrázky nebo je lepší překladatel než člověk, takové články opravdu vycházejí. To je často hodně přestřelené. Takový člověk se třeba snaží prodat svou firmu, nebo dělá v korporaci a chce získat bonus nebo rovnou povýšení. No a tak vydá bombastické prohlášení o tom, že počítač má na nějaké úloze nadlidský výkon.
Já dělal ve velkých korporacích roky a takových příkladů jsem viděl řadu. Když chce někdo mít úspěšnou kariéru, tak se snaží, aby o jeho práci vyšla bombastická zpráva. Taková se do médií dostane mnohem spíš. Pamatuji si třeba, že v roce 2012 v New York Times vyšla zpráva o tom, že se neuronová síť v Googlu naučila rozpoznávat objekty na videu bez supervize, jen sledováním YouTube.
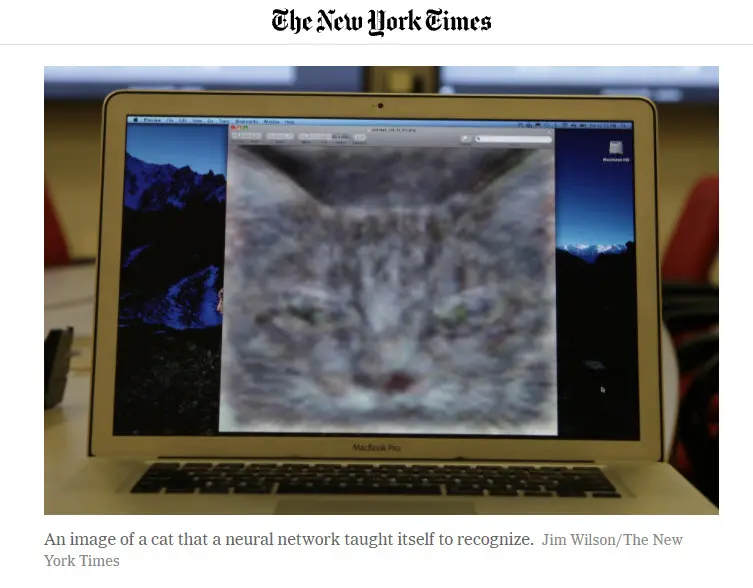
Fotografie v New York Times v červnu 2012 vyšla s popiskem: „Obraz kočky, který se neuronová síť sama naučila rozpoznávat.“
Ano, to si pamatuju, to tehdy vypadalo, že bude obecný klasifikátor hotový co nevidět.
Tehdy jsem se na to ptal lidí, co na tom dělali. A ten slavný obrázek kočky, na kterém to novinářům předváděli, tak ten prý vůbec nebyl vygenerovaný neuronovou sítí, jak se pak v médiích tvrdilo. Ten obrázek byl naopak zadán na vstupu, pak se prohnal tou neuronovou sítí a vyšla z toho zašuměná kočka (Vedoucího zmíněné práce jsme poprosili o komentář, zatím neodpověděl, pokud odpoví později, jeho odpověď do článku doplníme, pozn. red.).
Kdyby ten postup popsali správně, tak by to nikoho nezaujalo, protože to vlastně nedělalo nic moc jiného než to přidávání šumu. Začne to malým podvůdkem. Ale jak jednou člověk zalže, tak se to začne nabalovat, to je jako s tím Theranosem. „Fake it till you make it.“ (Falšuj to, dokud se ti to nepovede doopravdy, pozn. red.) Pak už musí člověk tvrdit, že mu to funguje.
Ale abychom nebyli jen negativní, jsou věci využívající neuronové sítě, které opravdu dobře fungují, ne? Vy sám jste třeba přispěl k tomu, že dnes strojový překlad celých vět funguje překvapivě dobře a výsledky jsou použitelné.
Ano, to je pravda. Strojový překlad vychází z neuronových jazykových modelů. To, co jsem dělal já ještě jako student VUT Brno, je jen malá část, nicméně tam to začalo. Ve své dizertační práci jsem už v roce 2012 strojový překlad testoval a fungovalo mi to velmi dobře na akademických datasetech. Bylo jasné, že bude problém ten model naškálovat na větší datasety, a bylo potřeba vyřešit, jak celý překlad realizovat od začátku do konce přes neuronové sítě, bez použití starších statistických modelů. S první verzí end-to-end neuronového překladače jsem přišel už v tom roce 2012 během internshipu v Microsoft Research. Později to dokázali dotáhnout kolegové v Googlu, ale na tomto pak dělaly desítky lidí a zabralo to ještě roky práce.
To už jsem z Googlu odešel, takže jsem to pak sledoval jen z vnějšku. Jedna věc je mít fungující prototyp systému překládající text, a druhá věc je, aby ten systém fungoval rychle a levně a byl dostupný pro miliony lidí. Musí být výpočetně dostatečně nenáročný, aby jej mohli lidé využívat na celé planetě. To už byly ale problémy, které řešili top inženýři v Googlu.
Ve velkých firmách se politikaří
Dělal jste ve všech firmách té velké trojky – Microsoft, Google i Facebook. Jak byste srovnal jejich vnitrofiremní kulturu?
V Microsoftu jsem byl na tříměsíční stáži v roce 2012, to už je skoro deset let. Byli tam opravdu dobří vědci. Ale nechtěl jsem tam zůstávat, protože tam tehdy fungoval ten systém „stack ranking“.
To si pamatuji. Každý vedoucí týmu musel seřadit výkon svých podřízených. Ti nejlepší byli povýšeni nebo dostali přidáno, ti nejhorší museli být propuštěni…
Musel to tak mít každý tým. Lidé v týmu si pak nepomáhali, ale soupeřili mezi sebou. Vedlo to k rozložení vztahů mezi lidmi, všichni byli na pohled velice milí, ale cítil jsem tam politiku. Ale já tam byl jen na stáži, to bylo super, a za ty tři měsíce jsme tam napsali s mým vedoucím tři články, takže to bylo velmi povedené. (Microsoft oficiálně ukončil kontroverzní metodu hodnocení stacked ranking v roce 2013, pozn. red.)
Z Microsoftu jste zamířil do Googlu, konkrétně do jeho tehdy nově založené divize pro strojové učení…
V Google Brain jsem začínal zrovna v době, kdy začínala ta obecná fascinace strojovým učením. Viděl jsem tam, jaký vliv má na lidi úspěch a peníze. Jeden kolega Googlu prodal svůj startup, a myslím, že ho to hodně poznamenalo. Když je někomu 26 let a má desítky milionů dolarů na účtu v podstatě za nic, z toho se člověk může trochu zbláznit.
Rok 2012 začala zlatá horečka strojového učení. Našemu oboru to ublížilo.
Byla to taková zlatá horečka strojového učení. Viděl jsem tam profesory, kteří se ještě před dvěma roky neuronovým sítím smáli. Najednou zakládali startupy věnované hlubokému strojovému učení (deep learning) a obratem je nabízeli ke koupi, bez jakéhokoliv produktu nebo inovace. A často i uspěli. Podle mne toto našemu oboru ublížilo, přilákalo to spoustu zlatokopů. Místo zajímavého výzkumu se pak často hledalo, jak ty přehnané vize předvést médiím.
Tak vznikají ty předváděčky, které vypadají úžasně, ale když se začnete zajímat, kde si to taky můžete vyzkoušet, tak zjistíte, že to bylo jenom naaranžované video a předváděný systém nikdy neexistoval. Samozřejmě ne vždy, ale často tomu tak bylo.
Strojové učení se dělá v Pythonu, umělá inteligence v PowerPointu.
V Silicon Valley a pak později v New Yorku jsem opravdu zažil, že lidé prezentovali technologie, které nikdy neexistovaly. A byli za to i povyšováni, když měli známého na manažerském postu. To už je korporátní život.
A třetí stanice byl Facebook…
Zatímco v Googlu šlo o to, aby náš tým zpřístupnil technologie pro strojové učení zbytku firmy, tak u Facebooku se od začátku mluvilo o základním výzkumu umělé inteligence. Budeme zkoumat ty věci, které ještě neexistují, budeme se dívat deset let dopředu. Měli jsme se soustředit na publikování nových nápadů a přístupů. Takový byl aspoň ten původní cíl. Ale i tady byly stejné problémy jako všude jinde. Nechci zabíhat do podrobností. Lidé se rychle dostávali do čela s něčím, co nikdy nefungovalo.
Umělá evoluce a umělý chaos
Takže jste se vrátil do akademické sféry do Prahy.
V Evropě je ve výzkumu mnohem méně peněz a paradoxně to asi pomáhá tomu, že jsou tu pak lidé férovější a čestnější. Prostě u nás dělají výzkum spíše nadšenci, které to baví. To mi sedí více než to americké „fake it till you make it“. V Americe mi vadilo, když kolegové říkali na veřejnosti úplně jiné věci, než kterým sami věřili.

Chci dělat výzkum, který má šanci vést k novým přelomovým objevům, rád bych viděl něco překvapivého. Delší dobu jsem uvažoval, že se vrátím do Evropy, a na ČVUT jsem dostal příležitost založit svůj tým v rámci CIIRCu. Mám tu pár studentů, se kterými zkoumáme komplexní systémy, modely umělé evoluce a vůbec témata mimo mainstream strojového učení.
Čím se momentálně zabýváte?
Můj plán je dělat na základním výzkumu umělé inteligence. Chci pracovat na algoritmech, které ještě nejsou – na rozdíl od strojového učení – tak dobře prozkoumané. Nesupervizované učení je pořád otevřený problém. Nyní je úspěšné strojové učení, které se trénuje na označených datech, kde jsou miliony trénovacích příkladů. Ale není jasné, jak použít strojové učení tam, kde není jasné, která odpověď je správná, kde nejsou data, ze kterých se učit. Ten výzkum je stále v podstatě na začátku. Existují třeba různé pokusy s reinforecement learningem (česky zpětnovazební učení, pozn. red.), který nepotřebuje při trénování vidět jasné příklady správných odpovědí. Tento přístup, zdá se, funguje pro nalezení řešení některých her, ale musí se zase řešit, jak nastavit odměny, jak je propagovat v čase, aby se počítač neučil jen z té odměny na konci hry apod.
Děláme s technikami, které mají potenciál fungovat pro nesupervizované učení. Když chceme vytvořit umělou inteligenci, myslím, že se k tomu můžeme dostat – paradoxně možná rychleji – simulací evoluce, spíše než abychom se snažili kopírovat lidský mozek, jehož složitost je obrovská. Mozek je vedlejší produkt evoluce. Myslím, že v budoucnosti se ukáže, že je nakonec jednodušší vytvořit systém umělé evoluce, kde bude potenciál pro vznik umělého mozku, než se snažit počítačově napodobit biologický mozek.
Co by měli rodiče říci dětem o umělé inteligenci? Co budou děti muset znát v tom novém světě?
Neřekl bych, že budou něco muset, spíše, že budou moci dělat nové věci, dostanou nové příležitosti. Strojové učení je příležitost, jak automatizovaně řešit spoustu problémů, které do teď museli řešit lidé manuálně. Do budoucna to budou zvládat počítače, ať už jde o kontrolu kvality výrobků v továrně, nebo o analýzu velkých dat.
Ve zdravotnictví je velký potenciál pro využití strojového učení. Počítač dokáže objevit závislosti, které by člověk neuměl ani pojmenovat. I zdánlivě hloupé modely dokáží zázraky, když jim dáte velké množství dat.
Počítače vidí v datech takové vztahy, které tam běžní lidé nevidí. Třeba zdravotnictví je příklad zatím nevyužité příležitosti, je tam ohromné množství dat. Na to ani není potřeba inteligentní počítač, stačí dobrá statistika. Počítač dokáže zanalyzovat mnohařádově víc dat, než by člověk přečetl za celý život. Najde tam vztahy a závislosti, které jsou z hlediska počítačového modelu jednoduché, ale pro nás jsou skryté.
Vědci by takové vztahy jen těžko objevovali v nějaké studii, ale počítač to statisticky odhalí na ohromném vzorku zdravotních dat. Objevíme v tom, jak má kdo cvičit, co má jíst, jak lépe spát, aby byl zdravý. Prevence nemocí by se dala skokově zlepšit právě použitím strojového učení a digitalizací zdravotnictví.
Najdeme individuální, personalizované doporučení pro prevenci, ale i léčbu různých nemocí. Dnes jsou ta doporučení velmi obecná a nepřesná, jako například: muži přes 40 let mají jít na ten či onen test jednou za pět let. Počítačové modely budou mnohem přesnější.
Jestli jsme si ve světě strojového učení něco osvojili, tak je to poznání, že i zdánlivě hloupé modely postavené na velkém množství dat mohou dělat málem zázraky. Věřím, že až se začne technologie, původně navržená pro to, aby vám doporučila personalizovanou reklamu na pizzu, používat pro prevenci nemocí, tak na tom všichni ohromně získáme.
Tématem Hacker kongresu v Paralelní Polis, na kterém jste letos přednášel, byl Chaos. Jak se chaos týká vašeho tématu umělé inteligence?
Se svými kolegy studujeme různé aspekty chaosu v rámci té naší matematické evoluce. Vytváříme různé matematické modely, které z jednoduchých pravidel vytváří komplexní chování. Trochu to vypadá jako slavná Game Of Life, zkrátka jednoduchý automat, kde postupem času vznikají samovolně stále více složité vzory.
Klasický chaos je definovaný ve spojitých systémech tak, že když minimálně změníme počáteční podmínky, tak se zásadně změní výsledek v budoucnosti. My se snažíme definovat chaos i v diskrétních (nespojitých) systémech, kde je to stále otevřený problém. Letos měla moje studentka Barbora Hudcová článek na toto téma na konferenci ALife, kde ukázala, jak bychom mohli chápat chaos v diskrétních systémech. V podstatě jde o to, že se snažíme ukázat, že chaotické systémy nejsou schopné provádět užitečné výpočty.
Když mluvíte o strojovém učení, používáte občas podobné termíny, které používají pedagogové. Nakolik lze strojové učení přirovnat k lidskému učení?
Lidé se umí učit kontinuálně, vytváříme si stále nové modely světa, které jsou složitější a složitější a staví na tom, co jsme se naučili dříve. Je rozhodně zajímavé toto zkoumat. Ale taky v našem oboru používáme trochu zavádějící terminologii. Například existuje hodně pokusů a hromada článků, jak to udělat, aby se strojové učení naučilo se učit, jak se učit postupně jako lidé stavěním nových řešení na základě těch předchozích. Ale to jsou zrovna problémy, které současné strojové učení dobře neřeší. Možná by bylo lepší mluvit o strojovém memorování, protože ta potřebná generalizace tam stále chybí.
Počítač dotáhne naši kreativitu
Hodně se v posledních letech mluví o neuronových sítích, které umí generovat text nebo obrazy. GPT-3 dosahuje místy velmi věrohodných výsledků a umí na základě zadání psát i dlouhé souvislé texty, u kterých bych opravdu nepoznal, že jsou stvořené automatem. Nově pak představili Codex, který umí dle zadání dokonce programovat. Co říkáte na tyto projekty?
Nesleduji to detailně, ale samozřejmě mám radost, že lidé trénují větší a větší neuronové jazykové modely. OpenAI na tom nějak spolupracuje s Microsoftem (GitHub Copilot, pozn. red.), dává to smysl.
Jazykové modely založené na neuronových sítích se dají použít na libovolná sekvenční data. To nemusí být přirozený jazyk (jako angličtina nebo čeština, pozn. red.), to může být C++ nebo cokoli. Dá se to použít na automatické hledání chyb, na doplňování kódu. Můžete do zdrojového kódu napsat jen komentář, a automat vám dopíše celou funkci. Toto má velký potenciál do budoucna, hlavně pokud bude docházet k postupnému zlepšování.
Programátoři si často mohou myslet, že řeší nějakou unikátní úlohu, ale ve skutečnosti programují něco, co v nějaké formě už naprogramovalo tisíc lidí před nimi.
Opět to ukazuje sílu velkých dat. Programátoři si často mohou myslet, že řeší nějakou unikátní úlohu, ale ve skutečnosti programují něco, co v nějaké formě už naprogramovalo tisíc lidí před nimi. Ten použitý model sice nemá žádné komplexní chápání nebo motivaci, ale přečetl taková kvanta dat, že dokáže dobře doplnit znalosti lidí.
Umím si představit spoustu dalších takových aplikací do budoucna. Běžný člověk bude moci psát jako profesionální spisovatel. Prostě místo toho, aby počítač překládal z francouzštiny do češtiny, tak bude překládat z „obyčejné češtiny“ do češtiny ve stylu nějakého spisovatele.
Co umí GPT-3?
Neuronová síť GPT-3 (Generative Pre-trained Transformer 3) využívá hluboké strojové učení ke generování textu na základě zadání. Síť je natrénovaná na miliardách článků dostupných na internetu. Výsledkem jsou překvapivě souvislé, srozumitelné a smysluplné odstavce textu, které vyhovují zadání. Společnost OpenAI představila vylepšený GPT-3 v roce 2020 a nabízí jej zájemcům k otestování i k pronájmu.
GPT-3 umí řadu věcí: velmi obstojně generovat text v různých stylech, odpovídat na vědomostní otázky, analyzovat text nebo dokonce programovat.
Jako když někdo diktuje text, ale ten přepisující rovnou za běhu dělá úpravy, aby byl ten výsledný text srozumitelnější…
Právě, ale to je jen začátek. Dokážu si živě představit, že třeba napíšete povídku tak, že jen stručně načrtnete děj, počítač vygeneruje dlouhý text a vy pak jen budete měnit jednotlivé pasáže. Počítač podle toho bude nabízet různé varianty a alternativy. Za pět minut máte povídku, a můžete si ji pak upravit třeba do stylu Tolkiena. Takových nástrojů, které budou využívat jazykové modely, bude v budoucnu hodně.
Jaká nesmyslná prohlášení z oblasti neuronových sítí můžeme očekávat v následujících letech?
Určitě to bude něco, co hraje na strunu emocí. Třeba robot, který se učí vnímat svět jako dítě. Lidé si promítají lidské vlastnosti do všeho, co má obličej a mrká očima. Je to takový magický trik, jak přilákat pozornost a investice. Jinak ale doufám, že v budoucnu už lidé přestanou naslouchat fantaskním vizím futurologů a spíše se zaměří na věci, které opravdu existují. Nebo v případě výzkumu na věci, které by existovat mohly.
Přitom tam, kde se strojové učení reálně používá, žádné mrkající oči nepotřebují. Analyzují velká data, vytvářejí automatizované závěry a ty používají v praxi.
Nechci být pořád za pesimistu, ale prostě se mi nelíbí, že někteří lidé z AI komunity slibují nesmyslné věci. Podobně, jako je dokument o podvodech firmy Theranos, tak by to chtělo natočit dokument o tom, jak se podvádí v oblasti umělé inteligence.
Je potřeba vztahovat sliby k realitě. Třeba slavná prezentace, jak z Googlu volal automat do restaurace, aby vytvořil rezervaci a v restauraci vůbec nepoznali, že jim volá robot… Google Duplex. Nějací novináři do toho šťourali a zjistili, že na straně restaurace byl najatý herec, jelo se podle scénáře, vyzkoušet ten systém samozřejmě nešlo.
Ale někde už strojové učení ukazuje přesvědčivé výsledky, které si lidé vyzkoušet mohou. Třeba generování obličejů…
To je také docela komplikované téma. Je těžké dokázat, že je nějaký vygenerovaný obličej opravdu nový, a ne jen lehce pozměněný příklad z trénovacích dat. Dá se třeba hledat nejbližší „soused“ toho obrázku v trénovacích datech na úrovni pixelů, ale je celkem snadné tuto kontrolu obejít.

Tito lidé neexistují. Vygenerovala je síť StyleGAN2 od výzkumníků z firmy NVIDIA.
Stačí obrázek otočit nebo změnit osvětlení, a tato kontrola nebude fungovat. Už jsem ale viděl i videa, jak se generované obličeje plynule mění, to už pak vypadá přesvědčivě.
Zcela jistě máme mnoho skvělých výsledků v oblasti strojového učení, problém vidím v tom, že je k nim přidána i řada věcí, které tak úplně nefungují. Je to často velmi těžké rozlišit, sám jsem několikrát v minulosti uvěřil tomu, jak je nějaká nová technika skvělá, aby se později ukázalo, že tomu tak není.
Reklamy používaly strojové učení hned
Také u překladů musím říci, že strojové učení zkrátka dává užitečné výsledky. Překladač DeepL mi dává na výběr z různých variant překladu a přizpůsobí tomu pak zbytek textu.
Ano, to vypadá velmi dobře. Nevím, jak se liší postup DeepL od Google Translate, tipoval bych, že používají podobné techniky, ale třeba to mají trénované na kvalitnějších datech. Nemyslím si, že by měli nějaké tajné know-how na straně technologií.

Nebo prostě používají větší neuronové modely. Protože Google Translate sám o sobě nevydělává, běží zadarmo a musí dávat odpovědi okamžitě mrakům lidí po světě. Je tedy možné, že DeepL prostě dává lidem k dispozici přístup k výpočetně náročnějšímu modelu, protože za tím mají byznys model. Takže možná je to stejná technologie na podobných datech, ale s větším modelem. Je to ale jen tip, nevím, zda to tak je.
Není paradox, že ty nejlepší mozky světa teď pracují na tom, že krmí počítač daty a trénují jej?
Když jsem začínal v Google, tak tam třeba tým o třiceti lidech řešil synonyma slov. Aby mohli dávat lepší výsledky vyhledávání na uživatelské dotazy. Měli tam různé tabulky slov se stejným významem, byly za tím roky a roky práce, ale žádná raketová věda. Přitom tam pracoval jeden člověk, který tam původně přišel z vědecké pozice v NASA. Předtím posílal rakety do vesmíru, teď vytvářel tabulky synonym. Ale za mnohem lepší plat.
Z pohledu peněz by se zdálo, že největší problém současné matematiky je, kdo dá čemu lajk…
Nebo ještě spíše, kdo klikne na jakou reklamu. Tam jsou ty skutečné peníze. To je ta hlavní metrika, která se optimalizuje. Reklamní systémy byly v korporacích ta první věc, která začala používat strojové učení. Když jsem začínal v Google Brain v roce 2012, byl jsem překvapen, jak málo se používalo strojové učení ve vyhledávači. Tehdejší šéf vyhledávání, Amit Singhal, to přímo blokoval, říkal, že nechce mít ve vyhledávači něco, čemu nerozumí a co nemá pod kontrolou. Takže všechno se dělalo přes pravidla, jen s minimem strojového učení.
Naopak reklamní systém používal strojové učení už od začátku. Tam byli lidé mnohem progresivnější. Když to zlepšilo metriku, tak se to používalo. I ten Word2Vec tam hned aplikovali všude, kde se dalo, a vydělávalo jim to peníze už v době, kdy lidé z vyhledávání ještě váhali.
Každé slovíčko má své místo
Jste dodnes známý jako „ten, co vytvořil Word2Vec“?
Asi ano. Přitom já bych řekl, že jsem z vědeckého hlediska měl mnohem více přelomový výsledek jinde. Jednak jsem byl první, kdo dokázal úspěšně trénovat velké rekurentní neuronové sítě v době, kdy tyto modely byly považované vědeckou komunitou za nenatrénovatelné. Vůbec první netriviální úspěchy deep learningu v oblasti zpracování jazyka byly moje články o rekurentních neuronových jazykových modelech. Ale pak se stal známějším ten můj další projekt Word2Vec. Asi proto, že jsem to vydal v době, kdy jsem dělal v Googlu, a to pak má mnohem větší ohlas.
A není to také tím, že Word2Vec může skoro kdokoli implementovat?
Ano, je to jednoduché, dá se to snadno pochopit. A kdokoli si může stáhnout nějaký textový soubor, natrénovat si model a pohrát si s ním.
Článek o Word2Vec jste sepsal s Jeffem Deanem, jedním z nejznámějších programátorů z Google…
Já jsem tehdy chtěl řešit něco úplně jiného. Když jsem v roce 2012 nastoupil do Google Brain, tak jsem se tam nejprve rozkoukával, neměl jsem žádný přiřazený úkol. Chtěl jsem zlepšit Google Translate, to byl můj střednědobý plán, a dlouhodobý plán bylo pracovat na výzkumu umělé inteligence.
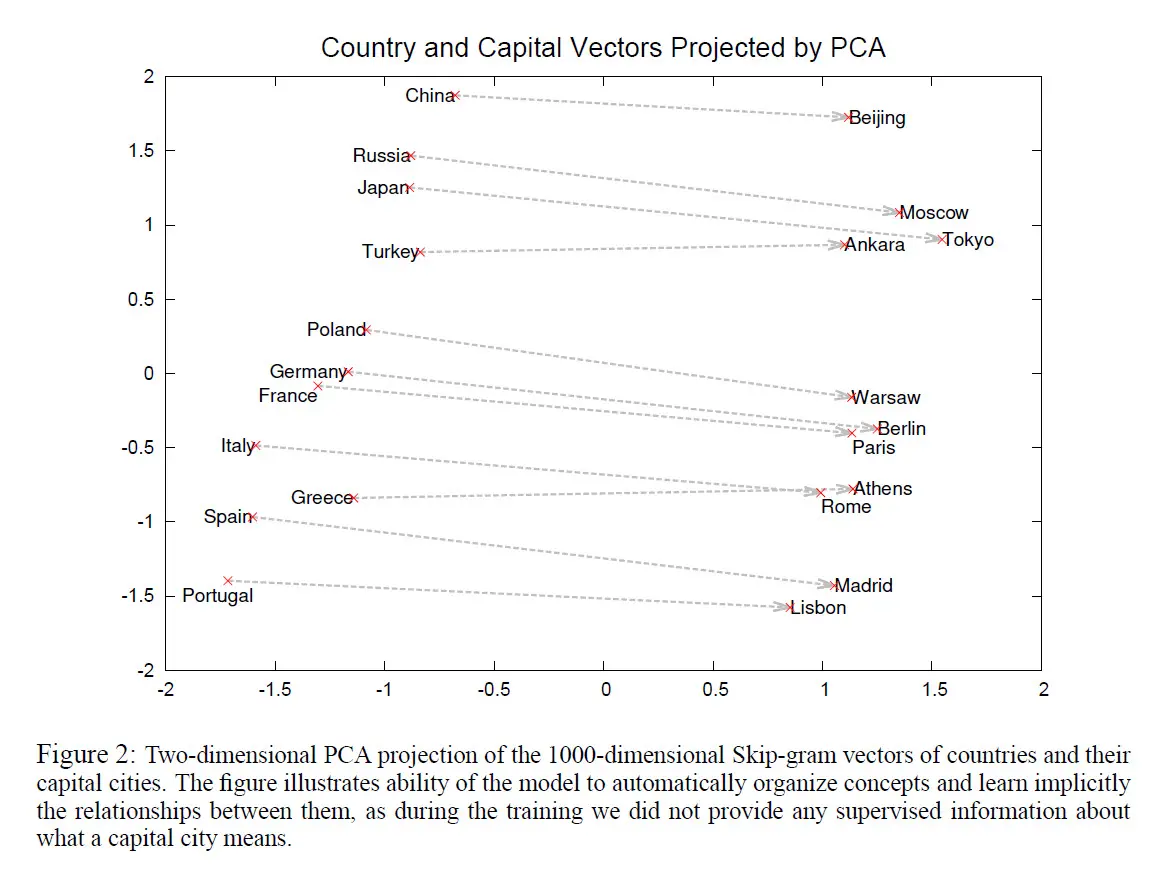
Ukázka z práce z roku 2013, kde Mikolov s kolegy z Google Brain představili možnosti Word2Vec. Natrénovaný model ve vektorovém prostoru vykreslí slova podle toho, jak jsou v textu používána. Například názvy zemí se pak nacházejí v podobném „směru“ od svých hlavních měst. Algoritmus lze využít na hledání synonym i vztahů mezi slovy.
Ale můj krátkodobý plán bylo udělat nějaký malý projekt, abych lidem kolem ukázal, že když mluvím o neuronových jazykových modelech, tak tomu rozumím. Přece jen jsem tam byl nový. Několik týmů tam tehdy používalo ty slovní vektorové reprezentace (umístění slov v mnoharozměrovém vektorovém prostoru, pozn. red.). Měli k tomu docela zbytečně komplikované modely, moc nad jejich architekturou nepřemýšleli. Někde tu metodu zkopírovali a ono to pak potřebovalo mraky počítačů na ten trénink.
Jeff Dean s pár dalšíma lidmi trénoval nějaký model na stovce počítačů. Šel jsem za nimi s tím, že by se to dalo dělat efektivněji, ale jejich zájem byl spíše v řešení paralelizace toho trénování. Tak jsem si k tomu sedl a relativně rychle jsem udělal model, který trochu fungoval, a dále jsem jej inkrementálně vylepšoval několik týdnů. Nakonec jsem dokázal překonat ten Jeffův model i s malým zlomkem výpočetních prostředků.
Pak jsem strávil skoro celé Vánoce 2012 sepisováním článku, na začátku ledna byl totiž deadline na konferenci, na kterou jsem chtěl poslat ten článek. Spoluautoři mi mezitím pomáhali vylepšit článek a přijít s větším datasetem k testování kvality výsledného modelu. Mimochodem, zrovna ten můj článek tehdy na konferenci zamítli. A když jsem jej pak vydal na jiné konferenci, tak se z něj stal jeden z nejcitovanějších článků v oblasti zpracování jazyka.






