





Článek
Článek si také můžete poslechnout v audioverzi.
Čtete ukázku z newsletteru TechMIX, ve kterém Pavel Kasík a Matouš Lázňovský každou středu přinášejí hned několik komentářů a postřehů ze světa vědy a nových technologií. Pokud vás TechMIX zaujme, přihlaste se k jeho odběru!
„96 % vašeho textu nese známky generování pomocí umělé inteligence,“ nahlásil mi jeden online ověřovač, který slibuje, že rozpozná texty vytvořené AI. Po sociálních sítích už nějakou dobu létají podobná obvinění. Nějaký důležitý text (například akademická závěrečná práce) totiž podle takového verdiktu vznikl nikoli poctivou lidskou prací, ale pomocí ChatGPT či podobného generátoru.
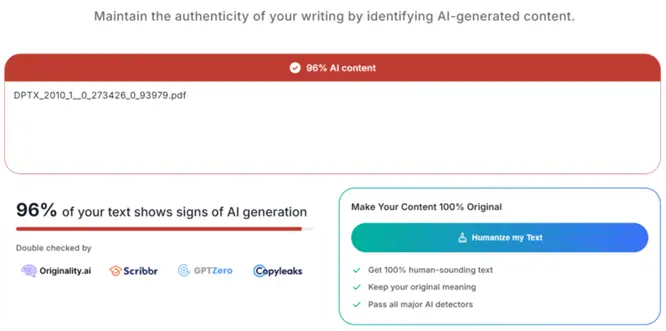
Výsledek detekce AI textu.
96 procent je nepochybně víc, než jsem čekal. Zvlášť proto, že zmiňovaný text je moje diplomová práce. Při její tvorbě jsem použil hodně věcí: Literaturu, zelený čaj, energetické nápoje, experimentální přístup ke spánku, překvapivě nespolehlivý nástroj pro formátování citací a nakonec i sdílenou tiskárnu u taťky v práci. Co jsem určitě nepoužil, je generativní AI: Práci jsem obhájil v roce 2012, kdy neuronové sítě opravdu s psaním textu ještě pomáhat neuměly.
Proč dává generátor tak nespolehlivé výsledky? V tomto případě to můžeme odvodit z jeho byznys modelu: Generátor nabízí studentům, aby si (za peníze) nechali přepsat práci tak, aby prošla detektory AI textů. Je logické, že jeho tvůrci mají motivaci výrazně nadhodnotit odhad zapojení AI.
Ani to moc neskrývají. Poté, co studenta vyděsí hláškou „96 % tvého textu vypadá, že jej vygenerovala AI“, totiž okamžitě nabídnou, že text „polidští“. Toto údajné přepsání provedou podezřele rychle: Moje diplomka má 194 stran, ale „humanizing process“ trval pouhých deset sekund, což je mimo realitu současných jazykových modelů. A pak už se studentovi ukáže nákupní obrazovka s nabídkou, že si polidštěný text bude moci za dva dolary stáhnout s příslibem, že teď už všemi detektory projde…
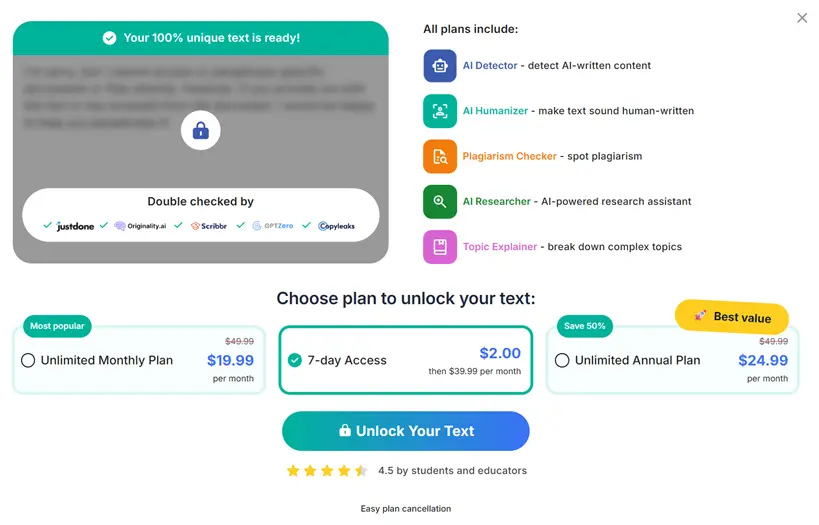
Nástroj slibuje, že když zaplatíte dva dolary (asi 43 Kč), můžete si stáhnout text, který projde jakýmkoli AI detektorem.
Protože takovouto službu považuji za přinejmenším manipulativní, nepošlu jim ani ty dva dolary. Chci ukázat něco jiného: Detekování AI obsahu není spolehlivé. Upozorňoval jsem na to už v květnu roku 2023, když bylo generování textu spíše raritou. Teď je ale generovaný text skoro všude: Na sociálních sítích, v e-mailech, v reklamách, v novinách i ve vyhledávačích. Je tedy načase si ujasnit, jak – a zda vůbec – dokážou lidé texty vygenerované umělou inteligencí rozpoznat.
Když chybí důkazy
První, co řadu z nás při přemýšlení o AI textu napadne, je přehodit řešení zpátky na technologie. Proč by nějaká umělá inteligence nemohla spolehlivě detekovat text, který sestavila stejná nebo jiná umělá inteligence?
Má to jakousi vnitřní logiku, zvláště pokud o generátorech uvažujeme velmi abstraktně. Jakmile se ale podíváme generátorům textů pod kapotu (jako jsem to tady zkusil já), zjistíme, proč je automatická detekce AI textů složitější než třeba detekce plagiátů.
Detektor opsaných textů – už dlouho běžná součást kontroly vysokoškolských prací – pracuje s ověřitelnými a především prokazatelnými fakty. Ukáže po provedené kontrole nejen číslo (například: „20 % textu vykazuje shodu s materiály, které nejsou správně citovány“), ale také nabídne přesný a dohledatelný přehled, odkud tyto nepřiznané citáty pocházejí.
Posuzovatel tak může snadno ověřit, zda nejde o chybu nebo nepochopení kontextu. Některé detektory třeba označují časté fráze jako „V souladu s platnou a účinnou legislativou České republiky“ nebo „Získaná pevná látka byla promyta“. Prostě věty, které jsou dokola opakované v řadě akademických textů, ale nejde o plagiát, spíše o žádoucí rigiditu v daném oboru.
Naproti tomu detektor AI textů žádné takovéto zdůvodnění nenabídne. Nemá jak. Posuzuje totiž hlavně pravděpodobnosti slov jdoucích za sebou. Odpovídá na otázku: „Jaká je šance, že by umělá inteligence tuto větu dokončila tak, jako je tomu v tomto textu“.
Pokud tedy studentova práce často sahá po „logických“, „očekávatelných“ a „konzistentních“ závěrech, detektor takovému textu přiřadí vysokou pravděpodobnost použití AI. Nedokážou ale kontrolora nasměrovat k žádnému konkrétnímu důkazu. Žádný totiž nemají. Jsou to jen dojmy, byť statisticky podložené.
Detektory jsou nespolehlivé a spíše škodí
Toto statistické podložení je ale hodně na vodě. Platí pro průměrné texty vygenerované AI. Studenti jsou možná líní napsat práci od začátku, ale nejsou líní naučit se text upravit a polidštit. I výše zmíněný nástroj, když studenti chtějí, umí skoro jakoukoliv detekci obejít.
Na webu je celá řada tipů a triků, které radí, jak AI text polidštit, zanést do něj drobné chyby a rozhodit tak lidské i automatizované detektory („napiš to jako mírně opilý student ve tři ráno“). Čím více práce si někdo s generováním dá, tím menší šance je, že půjde takový „generát“ odhalit (generát je to, co vypadlo z generátoru; moje vlastní slovo, které tímto dávám veřejně k dispozici). Rozhodně tedy nelze zaručit, že by detektory pomohly odhalit všechny (nebo alespoň většinu z nich), kteří si práci usnadnili.
Na opačné straně jsou falešné detekce (false positives), tedy případy, kdy detektor označí za AI generát text, který při vzniku k žádné umělé inteligenci ani nepřičichl. Studenti obvinění z netransparentního generování textu jsou tak hozeni do prakticky neřešitelné situace: Mají při odvolání dokázat, že nepoužili AI.
Někteří to řeší tím, že se filmují u toho, jak práci píšou: „Jsem už teď paranoidní, že budu obviněna z něčeho, co jsem neudělala, a dostanu kvůli tomu horší známku,“ uvedla třeba 23letá studentka informatiky Leigh Burrellová. Od doby, co byla její práce automatickým detektorem označena za generovanou, se raději natáčí u toho, jak domácí úkoly řeší, a tato videa dává na YouTube, kde bude důkaz případně ke zhlédnutí.
Už od roku 2023 experti opakovaně upozorňují, že falešně pozitivní nálezy se často týkají studentů, pro které není angličtina jejich prvním jazykem. Ve srovnání s rodilými mluvčími mohou častěji sahat po jednodušších či méně pestrých větných konstrukcích, což upevňuje „jistotu“ detektorů, že text vznikl ve velkém jazykovém modelu (LLM).
Vzdala to i OpenAI
Počátkem roku 2023 se ještě dalo mluvit o tom, že detekce generovaných textů bude nějak reálně možná. Dva měsíce po uvedení ChatGPT jeho provozovatel – firma OpenAI – zveřejnil svoje plány na detektor AI textů. Už tehdy vývojáři zdůrazňovali, že se na něj nelze stoprocentně spolehnout (měl pouze 26% úspěšnost a devítiprocentní míru falešných detekcí).
O půl roku později OpenAI tento generátor přestala inzerovat: „Důvodem je nízká úspěšnost detekce. Pracujeme nyní na lepším ověření, které by vycházelo z detekce původu textu,“ uvedli vývojáři v červenci 2023.
V létě 2024 pak do médií pronikly spekulace o tom, že OpenAI by mohla do svého jazykového modelu přidat nástroj pro „tajné označení“ (tzv. watermarking). Takové označení by bylo pro člověka neviditelné a zřejmě by na detekci stačil i text o několika stech slovech. Druhou možností by bylo ukládání všech vygenerovaných textů na serverech OpenAI (což nyní kvůli provizornímu rozhodnutí soudu stejně musejí dělat) a následné vyhledávání v těchto textech. Tak by bylo možné skutečně dokázat, že text byl vygenerovaný umělou inteligencí.

Jenže OpenAI už zdaleka není jediná firma, která nabízí generátory textů. Kdyby takový detekční nástroj skutečně uvolnili, pravděpodobně by to vedlo k odlivu uživatelů, kteří by si místo toho vybrali konkurenčního chatbota. Detekce by stejně nefungovala, jen by tu byl další nástroj, který by sliboval falešnou jistotu.
Na trhu jsou už k dispozici open-source modely, například Lllama od firmy Meta nebo čínský Qwen, které jsou už pro běžné použití prakticky na stejné úrovni jako komerční modely. Iluze, že by se někdy mohlo podařit přesvědčit všechny zainteresované velké hráče k tomu, aby do svých modelů implementovali nějaké označení, se nástupem volně dostupných modelů zřejmě již definitivně rozplynula.
Samozřejmě nám stále zbývají instinkty. Můžeme mít pocit, že je text vygenerovaný, a ten pocit může být relevantní. Řada učitelů třeba dobře zná schopnosti svých studentů. Umí tedy poznat, kdy student využil chatbota k „prochytření“ referátu. Stejně, jako by v minulosti pedagog poznal, když za studenta referát napsali rodiče. Na sociálních sítích poznáme „generáty“ podle nadužívání smajlíků (typické pro GPT-4o).
Nový přístup k textu
Osobně nejčastěji poznám AI generát na základě disharmonie mezi účelem a délkou/sofistikovaností textu. Nástroje jako ChatGPT, Gemini i Claude jsou zkrátka velmi ochotní generovat dlouhé a smysluplné texty na jakékoli téma. Jako člověk, který se psaním živí, mám představu o tom, jak dlouho trvá napsat text, který má hlavu a patu. Takže když vidím dlouhý text na téma, které si dlouhý text nezaslouží, bliká mi v hlavě kontrolka „generováno AI“.
Zároveň si ale uvědomuji, že tato kontrolka už pro mne nemá stejný význam jako dříve. Zatímco před dvěma roky byly texty vygenerované umělou inteligencí obvykle jednoznačně horší, než co bych si chtěl přečíst, poslední rok už to tak není.
Čtu každý týden vyšší desítky textů od lidí (aspoň myslím, že jsou od lidí). A poslední dobou si od AI agentů nechávám každý týden dělat souhrny na různá témata, na základě často dost komplexního zadání. Někdy před půl rokem se hranice mezi těmito texty začala stírat takovým způsobem, že jsem musel zásadně přehodnotit, jak nálepku „AI text“ vnímám.
Už si prostě nevystačím s jednoduchou zkratkou „AI text je špatný a lidský text je dobrý“. Jsou super texty od lidí a jsou super texty od AI, jsou špatné texty od lidí a špatné texty od AI. Rozhodnutí, co si k danému tématu přečtu, tedy musím dělat jinak než na základě jednoduché dichotomie robot/člověk.

Pro některé účely je pro mne text od člověka nezastupitelný. Konkrétně jsou to texty popisující lidskou zkušenost, rozhodování a osobní pohled autorky či autora. Zkrátka texty, u kterých mi záleží na tom, že jim mohu věřit – tak, jako mohu věřit danému člověku.
Obvykle jsou to texty od lidí, které nějakou dobu sleduji anebo je mám nějak zprostředkovaně doporučené. Takový text pak beru jako „dárek“ od daného člověka, který za něj zároveň ručí. Nejen svou reputací, ale i časem. Vždyť mohl ten týden (ano, dobré texty vznikají dlouho) věnovat čemukoli a věnoval jej právě tomuto. Od některých autorů si tak s chutí přečtu i text o něčem, co mě jinak vůbec nezajímá. Mají mou důvěru a věřím, že by neplýtvali svým časem na něco, o čem nemá cenu psát.
Samostatnou kapitolou je pak beletrie, kde mě text baví číst právě proto, že vznikl v mozku mého oblíbeného autora. Umělá inteligence může napsat nové příběhy ze Zeměplochy, ale tato fanfiction nemůže konkurovat autentickým textům Terryho Pratchetta. Ne kvůli kvalitě, ale kvůli původu. Originál je jen jeden.
Ale v řadě jiných případů vím, že text vygenerovaný umělou inteligencí je pro moje účely dostačující. Když pronikám do nějakého nového tématu, nechám si zpracovat „učebnici na míru“. Má třeba 15 stránek, odkazuje na zdroje, vznikla na základě mých instrukcí a je – z mého pohledu – skvěle použitelná. Bere v potaz moje nápady a situaci, a přitom odkazuje na existující zdroje.
Takto vypadá ukázka z 80stránkového dokumentu, který jsem nechal AI zpracovat na téma dnešního newsletteru.
Samozřejmě si musím být vědom toho, že si AI i tak může bezostyšně vymýšlet, za každou cenu mne bude chválit, bude se mnou souhlasit a podlézat mi… Anebo mi dokonce může dávat zdraví nebezpečné rady.
Pokud vím o těchto limitech, mohu hledat, k čemu lze texty od AI použít. A kde naopak chci číst text od skutečných lidí. Tuhle hranici si bude každý muset někde stanovit. V průběhu času pak budeme – na základě svých zkušeností – tyto hranice posouvat.
Já to obvykle lidem říkám jednoduše: Kdyby někdo viděl, jak jste AI během tvůrčího procesu zapojili, cítil by se coby příjemce podveden? Nebo by naopak ocenil, že jste při tvorbě využili vše, co máte k dispozici, aby byl výsledek co nejlepší?
Stále platí, že novinářské texty pro vás píšu ručně (nefilmoval jsem se u toho, pardon). Není to proto, že bych neuměl chatbota přemluvit k tomu, aby za mne něco napsal. Dokonce to není jen kvůli našemu redakčnímu kodexu. Texty píšu proto, že mne to baví. Umožňuje mi to si k tématu sednout, rozebrat jej, přemýšlet o jeho aspektech. Vyprovokovat svůj mozek k tomu, aby tu hromadu vstřebaných informací zvážil, kriticky konfrontoval a poté prezentoval ve snad srozumitelné podobě.
Vydáním textu – respektive jeho zasláním příjemcům newsletteru – pak stvrzuji to, že si za tím textem stojím. Stálo mi za to věnovat mu svůj čas; a pokorně doufám, že ani oni nebudou těch pět nebo deset minut čtením strávených považovat za ztrátu času.
Věřím, že postupně se k tomu propracují i školy. Psaní textů nebude – už nemůže být – nástrojem pro ověření toho, že student věnoval nějakému tématu čas. To se bude muset ověřovat jinak. Použití generovaného textu pak nebude vnímáno jako podvod, ale jen jako jeden z mnoha nástrojů v arzenálu studenta.
Lidské uvažování, zaujetí, důvěra, soustředění a kritické myšlení mají smysl i v éře umělé inteligence. Jen budeme muset o všem (poněkud paradoxně) více přemýšlet.
V plné verzi newsletteru TechMIX toho najdete ještě mnohem víc. Přihlaste se k odběru a budete ho dostávat každou středu přímo do své e-mailové schránky.






