





Článek
Analýzu si také můžete poslechnout v audioverzi.
Když si ušpiníte tričko borůvkami, co uděláte? Nejspíš sáhnete po mobilu, ve kterém máte přístup ke všem informacím, které kdy lidstvo vyprodukovalo. A Centrálního Mozku Lidstva se zeptáte, jak se skvrny zbavit.
Dříve jste byli při vyhledávání vrženi do moře odkazů, ve kterých jste se museli zorientovat, posoudit je, na některé z nich kliknout… Zatímco borůvková skvrna pomalu proniká látkou, vy s trpělivostí detektiva vstřebáváte protichůdné rady z webů, o kterých jste předtím nikdy neslyšeli.
Klasické vyhledávání Google: odkazy a krátká ukázka z textu každé stránky.
Od roku 2023 se stále více lidí na podobné otázky ptá nikoli vyhledávače, ale konverzační umělé inteligence, tzv. chatbota. Ten napíše odpověď na míru, aniž byste museli chodit někam jinam. Největší vyhledávač světa Google už dva roky experimentuje s tím, jak zapojit chatbota přímo do výsledků. Od loňska se tzv. Přehledy od AI zobrazují ve vybraných zemích, ke kterým se od letošního května připojilo i Česko.
Souhrny od umělé inteligence jsou stručné, s důrazem na okamžitou užitečnost. Podle statistik Googlu jsou s nimi lidé spokojeni: „Máme přímé důkazy o tom, že AI přehledy zlepšují celkový uživatelský zážitek a že lidé vyhledávání s Přehledy od AI preferují,“ uvádí Alžběta Houzarová, manažerka komunikace české pobočky Googlu. „Z našich dat vyplývá, že díky Přehledům od AI lidé rychleji najdou potřebné informace a mohou snadno objevovat vše, co web nabízí.“
Jak se ale vůbec stalo, že web něco nabízí? Kde se vzal ten obsah? A kdo bude tvořit obsah budoucnosti, když většina lidí dostane odpověď přímo od chatbota a nebude chodit na webové stránky?
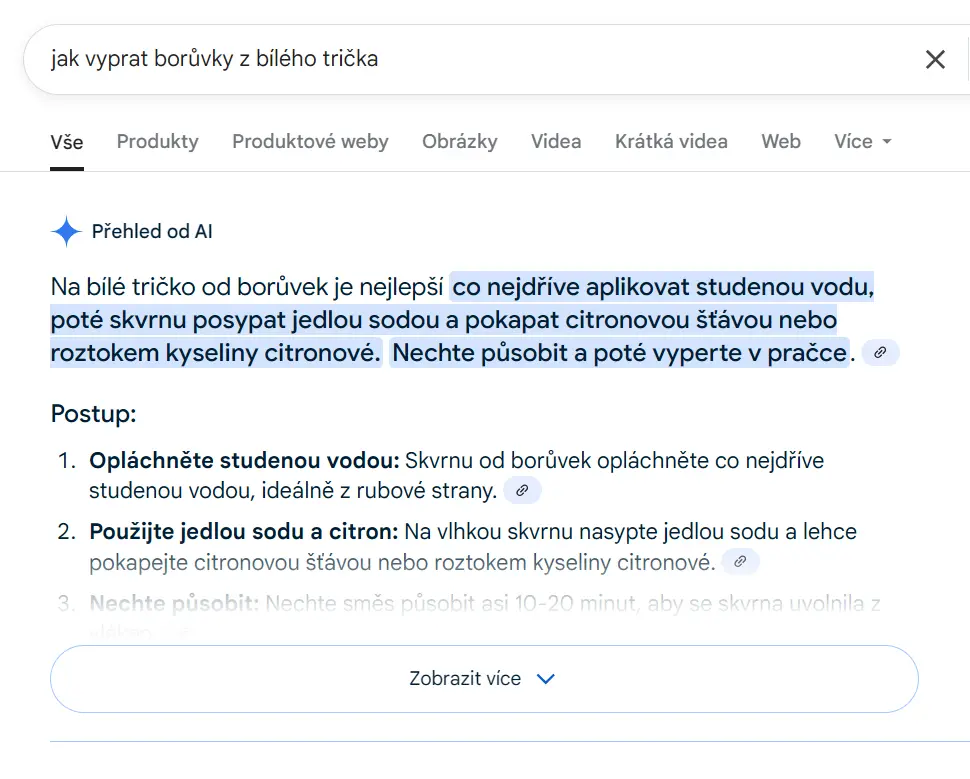
„Přehled od AI“ je funkce, kterou Google v Česku nabízí od května 2025. Zobrazuje se nad ostatními výsledky vyhledávání, text generuje umělá inteligence na základě obsahu nalezených stránek.
Starý dobrý web
„Snězte, co můžete!“ To je pozvánka nejen na fantastickou snídani formou bufetu, ale i lákadlo, se kterým přišla před 30 lety síť WWW, též známá jako web nebo prostě „internetové stránky“. Švédský stůl webového obsahu byl zpočátku chudý a nepřehledný. Pak ale přišly internetové vyhledávače a propojily tvůrce obsahu s konzumenty. Začal zlatý věk internetu: Cokoli jste na něm mohli najít, rychle, na pár kliků a zadarmo.
Samozřejmě tak úplně zadarmo to není. Nadšení je mocná motivace, ale časem se povedlo najít spolehlivější způsob, jak obsah nejen zafinancovat, ale také na něm něco vydělat. Během pěti let se na něj přeorientovaly skoro všechny weby: Byla to reklama, nejčastěji placená za proklik (PPC). Lidé přijdou na internetovou stránku, pár z nich klikne na reklamu, provozovatel dostane provizi a všichni jsou spokojeni.
Jak funguje internetová reklama
Reklama patří k nejčastějším zdrojům příjmů na internetu. Většina internetových vyhledávačů (včetně Google, Seznam, Bing a dalších) vydělává na reklamách. Na vyhledávači se reklamy zobrazují podle toho, co uživatel zrovna hledá. Jinde se reklamy mohou uzpůsobit tomu, co web o daném uživateli ví.
Reklama PPC – Inzerent platí pouze tehdy, když na reklamu někdo klikne (tzv. proklik). Inzerent si předem určuje cenu, kterou je ochoten za jedno kliknutí zaplatit. Reklamní platforma pak vybírá, kterou reklamu danému uživateli zobrazí. Pokud uživatel na reklamu klikne, inzerentovi se částka strhne z rozpočtu. Z anglického pay per click.
Reklama PPV – Inzerenti platí za reklamu bez ohledu na to, zda uživatel na reklamu klikne. Stačí, aby se zobrazila. Obvykle inzerenti předem platí za určitý počet shlédnutí (například za milion zobrazení). Z anglického pay per view.
Právě tento byznys model pomohl k ohromnému rozmachu webu a vyhledávače jako Google byly katalyzátorem tohoto děje. Spojovaly čtenáře a obsah, přitom vydělávaly na zobrazované reklamě. Zároveň vyhledávače posílaly čtenáře na cílové weby a na těch už bylo, jak s touto návštěvností naloží a jak na ní vydělají.
Některé weby zavedly formu povinných plateb (paywall) či dobrovolných příspěvků, jiné nabízely zboží či služby a velká část si vydělává právě zobrazováním reklam. Pro všechny byla každopádně klíčovou metrikou návštěvnost: Počet lidí, kteří na stránku přijdou. A právě těchto lidí, kteří na internetovou stránku skutečně dorazí, poslední dobou výrazně ubývá.
Roboti prohledávají, ale lidi neposílají
Vyhledávače jako Google, Bing nebo český Seznam si udržují informace o tom, co na kterém webu je. Dělají to pomocí speciálních zvědavých „robotů“, jednoduchých prográmků, které prolézají webové stránky a ukládají si k sobě kopii textů. Díky tomu mohou na základě uživatelského dotazu rychle prohledat celý web a nabídnout odkazy na stránky.
„Bývalo to tak, že za každé dvě návštěvy od vyhledávacího bota k vám vyhledávač poslal jednoho návštěvníka,“ vysvětlil letos v dubnu Matthew Prince, ředitel internetové bezpečnostní firmy Cloudflare. „Jedna věc se nezměnila, vyhledávací boti pořád prohledávají internet stejným tempem. Ale na weby posílají mnohem méně lidí.“
Podle jeho květnových odhadů je to nyní přibližně 15 návštěv od Googlebota na jednoho návštěvníka. A to je ještě Google velmi štědrý ve srovnání s chatboty. ChatGPT od OpenAI generuje 1500 robotických návštěv na jednoho reálného návštěvníka a konkurenční Claude má údajně poměr dokonce 6000 strojových návštěvníků ku jedné návštěvě člověka.
O kolik klesla návštěvnost po zavedení AI přehledů?
O jaké procento návštěvníků z vyhledávače Google weby vlivem nové funkce AI přehledů přijdou? Jedna se studií (publikovaná v dubnu 2025) zaznamenala na anglicky psaném webu průměrný pokles návštěv z vyhledávačů o 34,5 procenta.
Česká data (z konce května) ukazují, že dopady na návštěvnost se liší dle zaměření webu. U stránek týkajících se zdraví byl naměřen pokles o 32 %, u financí o 24 % a u stránek věnovaných automobilům byl pokles 14 %. Jiná odvětví zaznamenaly pokles nižší. Studie byla provedena v době, kdy se Přehledy od AI na českém Google zobrazovaly pouze u asi desetiny dotazů.
Zvláště pokles počtu návštěv z největšího vyhledávače světa některé weby hodně trápí. Čím dál víc čtenářů totiž najde odpověď na svůj dotaz hned v souhrnu od Googlu, aniž by museli někam klikat.
To byla do jisté míry pravda i dříve – fulltextové vyhledávače nabízejí různé souhrny, boxíky a výstřižky prakticky od samého počátku.
Ovšem s nástupem generativní AI jsou tyto texty vytvořené na míru danému uživateli. Často tam jsou přesně ty informace, po kterých se pídí. Tak proč by riskoval návštěvu nějakého neznámého webu?
Google připomíná, že v souhrnu od umělé inteligence jsou odkazy na původní webové stránky. Ne všichni čtenáři si ale budou tyto drobné odkazy rozklikávat, naopak se dá očekávat, že to bude spíše výjimka. Jakmile se naučí, že mohou AI souhrnům důvěřovat (což zdaleka ne vždy platí), návštěvnost webů dál poklesne.
Jak a proč si AI vymýšlí?

„Mění se chování uživatelů,“ pozoruje Martin Malý, publicista a odborník na mediální inovace. „Je potřeba se smířit s tím, že pokud máte byznys postavený na návštěvnosti, můžete o velkou část snadno přijít. Musíte se poohlédnout jinde, buď po jiném zdroji návštěvnosti, nebo po jiném zdroji peněz.“
Návštěvnost už se nevrátí
Jako novináři mi samozřejmě záleží na tom, aby lidé četli původní články na našem webu, nikoli nějaké souhrny. Z těchto návštěv – a zobrazených reklam – žije většina médií a obsahových webů. Nicméně jako uživatel na sobě pozoruji, že tyto souhrny používám také a často mi stačí a nikam dál neklikám.
Jistě, když mi na něčem záleží, třeba když píšu tuto analýzu nebo potřebuji do nějakého tématu proniknout hlouběji, tak klikám ostošest. Jdu na původní weby, otevřu si desítky nebo stovky tabů (pro tento článek jich bylo „jen“ 114), a pak se tím postupně probírám.
Ale ve většině případů potřebuji jen něco rychle zjistit nebo ověřit. Do kolika je otevřená lékárna? Berou tramvaje v Drážďanech platbu kartou? Jakou teplotu má středně propečené hovězí? Jak se – hledám to dnes snad počtvrté – jmenuje šéf Cloudflare? Jakou technologii projekce má to nové planetárium v Praze?
Na žádnou z těchto odpovědí jsem nemusel nikam klikat, zatímco ještě před pár lety bych asi každým takovým dotazem přihrál nejrůznějším webům nějakou návštěvnost.
Nicméně když už někdo na odkaz v Přehledech od AI klikne, je takový proklik „kvalitnější“, vysvětluje Alžběta Houzarová z české pobočky Googlu: „Takoví uživatelé s větší pravděpodobností na webech, které navštíví, stráví více času.“ Je to zřejmě proto, že jde o zvídavější uživatele, kterým několik vět od umělé inteligence nestačilo a zajímají se o zdroj a další podrobnosti.
Ostatně na návštěvnost z vyhledávačů není žádný nárok: „Hned na začátku je nutné se vzdát představy, že je potřeba udržet stávající návštěvnost webu,“ zdůraznil Jan Tichý, konzultant v oblasti webové a datové analytiky. „To by bylo zásadní nepochopení úlohy webu v rámci zákaznických cest a obecně toho, co se vlastně teď děje.“
Naopak je podle něj současný krok naprosto logický: „To, že se z vyhledávačů přivádějících návštěvnost stanou dříve či později instantní odpovídače, které si uživatele obslouží samy u sebe, bylo jasné posledních 20 let. Bylo to jen otázkou času, kdy se to stane a jak to nakonec bude vypadat.“
S tím souhlasí i Martin Malý: „Svět, kdy se dalo spoléhat na stabilní návštěvnost z Googlu, docela rychle končí. Pravda ale je, že kdo stavěl svůj byznys na tom, že budou chodit lidé z Googlu – nebo ze Seznamu, Seznam Feedu, Facebooku, Twitteru a podobných zdrojů –, postavil ho na cizí půdě a nic z toho neměl jisté. Facebook to předvedl už před pár lety, Twitter (resp. X) do jisté míry taky, zažil jsem i odstranění webu ze Seznam Feedu a každá tahle zkušenost ukazuje, že závislost byznys modelu na službě někoho jiného je velmi křehká.“
Není to fér, není cesty zpět
Řada producentů obsahu přesto cítí pochopitelnou hořkost. Firmy jako OpenAI, Google nebo Anthropic totiž natrénovaly generativní jazykové modely právě na jejich obsahu. Cítí se jako provozovatel restaurace, ze které někdo v rámci nabídky „sněz, co můžeš“ vynesl kufry jídla. A pak je prodává ve své vlastní restauraci.
O největší část návštěvnosti zřejmě přijdou takové weby, které paradoxně svou existencí nejvíce přispěly jak k použitelnosti webového ekosystému, tak k existenci současných chatbotů jako takových.
„Nejhůř to odnesou weby, jejichž smysl chatboty plně nahradí,“ všímá si Tichý. „Tedy obsahové weby, jejichž hlavní funkcí bylo právě poskytování informací a odpovídání na uživatelské dotazy. Zároveň vůči nim to je nejméně fér – právě na jejich obsahu se AI učilo nejvíc, zcela zadarmo a bez jakékoliv protihodnoty – a teď je může citelně oslabit.“
Křivda je to očividná, ale není jisté, zda došlo k nějakému porušení autorského zákona. Někteří vydavatelé – z nejznámějších třeba New York Times – žalují OpenAI a Microsoft za porušení autorských práv a zdá se, že soud může být jejich stížnosti nakloněn. Jiné žaloby na AI firmy byly odmítnuty a soud se přiklonil k tomu, že trénování na datech není porušením práva autorů.
Připomeňme naopak, že některé weby už dlouho fungovaly pouze jako past na (ne)pozornost uživatelů. Nejčastěji jsou to automaticky generované články, které nenabízejí nic navíc, ale titulkem naznačují, že v nich uživatel něco užitečného najde.
Známý je také příklad on-line receptů: webová stránka má 15 odstavců s nepodstatným příběhem, dvě nesouvisející videa, osm reklam, dva newslettery… a teprve když se touto zbytečnou houštinou proderete, možná se dostanete k tomu, jaké ingredience budete potřebovat a jak při vaření postupovat. Není divu, že řada lidí raději řekne chatbotovi, aby jim udělal recept na míru. Horší než džungle těchto pro reklamu vytvořených stránek s recepty to být nemůže.
Ale co mají v nové situaci dělat weby, které ve skutečnosti mají čtenářům co nabídnout? „Optimalizace pro vyhledávače se zásadně nemění,“ domnívá se Pavel Ungr, který se na tento obor (SEO) specializuje. „Stará škola SEO zaměřená na pozice, kvantitativní zpětné odkazy a SEO články bez hodnoty je definitivně mrtvá už delší dobu.“
Tvůrci obsahu by se podle Ungera měli zaměřit na budování své značky, aby se stali důvěryhodnou autoritou ve svém oboru. Předpovídá ale konec éry, kdy vyhledávače braly obsah a vracely návštěvnost. „Nyní si berou obsah, ale vracejí velmi málo,“ připomíná Unger. „Otázkou je, jak na to tvůrci obsahu zareagují.“ Nabízí se vyjednávání, blokování chatbotů, nebo přesunutí obsahu za paywall. „Klíčové bude investovat do kvality místo kvantity, budovat skutečnou expertízu a rozložit rizika napříč platformami.“
U médií pak Malý vidí jako problém, že se příliš spolehla na technologické platformy: „Vydavatelé si vybudovali obchodní modely postavené na optimalizaci pro Google algoritmy místo na budování přímého vztahu s čtenáři. Pak se diví, že když Google změní pravidla, jejich byznys se otřese.“
Jaký vliv bude mít AI na internetový ekosystém?


Někteří vydavatelé se proti AI přehledům chtějí bránit soudně. Na začátku července podala Nezávislá aliance vydavatelů stížnost k Evropské komisi: „Vydavatelé nemají možnost zvolit, zda jejich obsah může nebo nemůže být použit pro Přehledy od AI ve vyhledávání Google,“ stojí v dokumentu podle Reuters. Podle nich tak Google zneužil své dominantní postavení.
Publicista Malý je k podobným stížnostem skeptický, připomíná, že vydavatelé jsou často závislí na návštěvnosti z Google: „Není to tak, že by Google kradl jejich přirozenou návštěvnost. Bez Google Search by většina z té návštěvnosti ani neexistovala.“
„Google prioritizuje přivádění návštěvnosti na web více než kterákoli jiná společnost,“ zdůraznila Alžběta Houzarová z české pobočky Google. „Díky novým AI funkcím ve Vyhledávání se lidé mohou nově ptát na více druhů otázek. A to vytváří další nové příležitosti pro objevování obsahu, firem i zboží.“
Pokus o řešení formou blokády
V červenci do boje o budoucí ekosystém webových stránek vstoupil poněkud nečekaně velký hráč, který dosud působil spíše na pozadí. Firma Cloudflare u všech svých klientů zavedla hromadné blokování AI chatbotů a jejich robotických „chapadel“. A protože Cloudflare zajišťuje zabezpečení provozu více než dvou milionů webů (dohromady tvoří asi pětinu celosvětové návštěvnosti webových stránek), jde o jeden z těch kroků, které mohou mít na výsledek určitý dopad.
„Internet již desítky let funguje na základě jednoduché dohody: vyhledávače indexují obsah a přesměrovávají uživatele zpět na původní webové stránky, čímž generují návštěvnost a příjmy z reklamy pro webové stránky všech velikostí,“ uvádí Cloudflare ve svém oznámení. „Tento proces odměňuje tvůrce, kteří vytvářejí kvalitní obsah, penězi i věhlasem. A zároveň pomáhá uživatelům objevovat nové a relevantní informace. A tento model je nyní narušen.“
Každý klient Cloudflare nyní může nyní zvolit, zda na jeho web budou mít AI agenti dveře otevřené, či uzavřené. A zatímco dosud si to musel každý web nastavit jednotlivě, nyní Cloudflare zatáhl za záchrannou brzdu a všem svým klientům nastavil jako výchozí hodnotu „STOP AI agentům“. Mělo by to mimo jiné zabránit tomu, aby se umělá inteligence trénovala na textech, aniž by k tomu majitelé obsahu dali souhlas. Cloudflare zároveň ukázal vizi toho, jak by autoři mohli na svých textech vydělat. Plánuje otevřít „tržiště“, kdy by mohly weby své texty nabídnout velkým firmám za dohodnutou finanční odměnu.
Není vůbec jisté, zda se tento pokus podaří. Ale oslovení experti se shodují, že stará rovnováha, která poháněla web od roku 2000, se rozpadala už dlouho. Nyní je její pád zjevně nezastavitelný. A tak je čas hledat nové modely spolupráce, které zajistí, že lidé budou mít motivaci dál tvořit kvalitní obsah.
Jinak skončíme v situaci, kdy veškeré články, které budeme číst, napsala umělá inteligence. Ta bude navíc trénovaná na čím dál starších a méně aktuálních textech. Což by byl nejhorší výsledek pro všechny.




