






Článek
Článek si také můžete poslechnout v audioverzi.
„Je v Praze na letišti pošta?“ Takhle jednoduše zní otázka, kterou jsem nedávno potřeboval urychleně vyřešit. Měl jsem mlhavou představu o odpovědi, logo pošty jsem na letišti určitě někdy zahlédl. Ale abych si byl jistý, radši jsem udělal to, na co jsem si za posledních 25 let zvykl, podobně jako většina lidí. Zeptal jsem se vyhledávače.
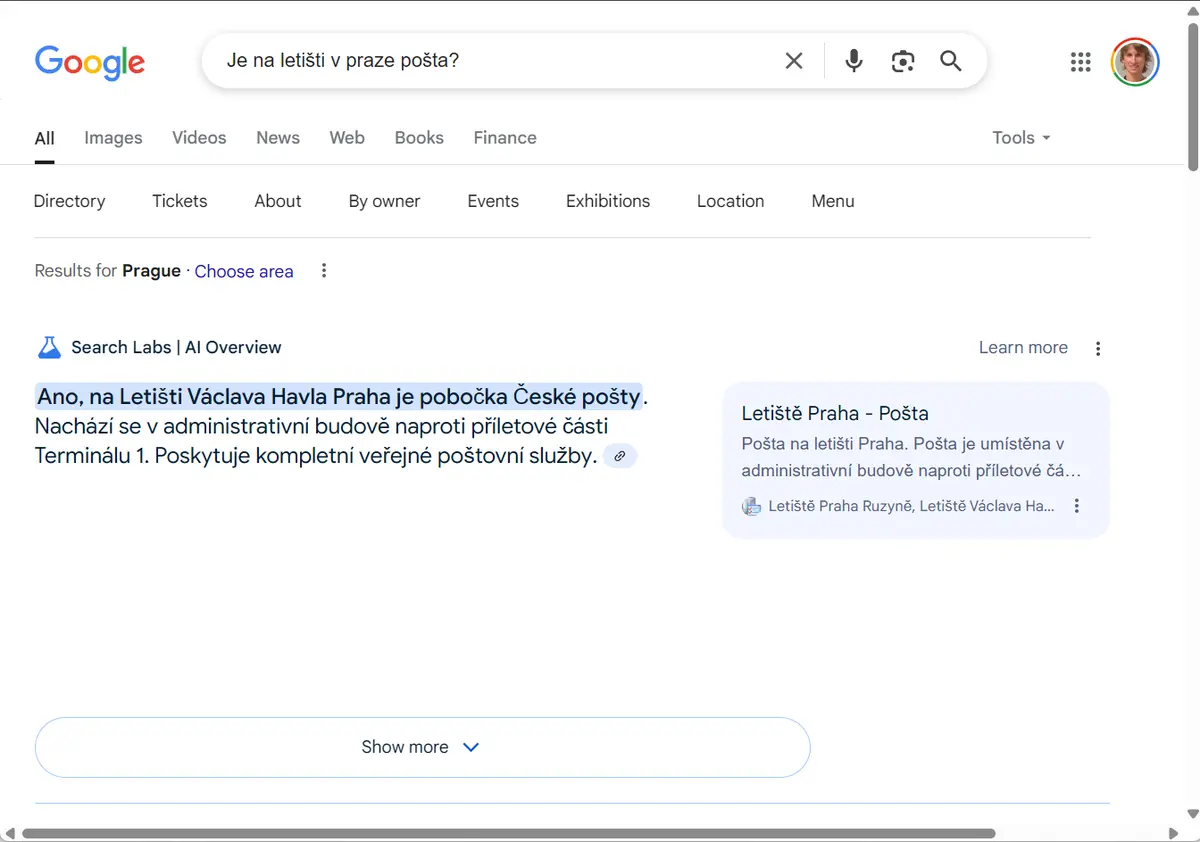
Odpověď vyhledávače, obohacená o AI souhrn. Google v Česku nabízí AI souhrny od dubna roku 2025.
Odpověď vyhledávače je velmi sebevědomá. Nejenže potvrzuje přítomnost pošty na pražském letišti, ale vysvětluje také, jak se tam dostat. Stejnou otázku jsem položil i nejpopulárnějším chatbotům současnosti. Jejich více či méně upovídané reakce byly ve vzácné shodě: „Ano, na Letišti Václava Havla je otevřená pobočka České pošty.“ Ani stín pochybnosti.
Podívejte se na odpovědi chatbotů a vyhledávačů (květen 2025):
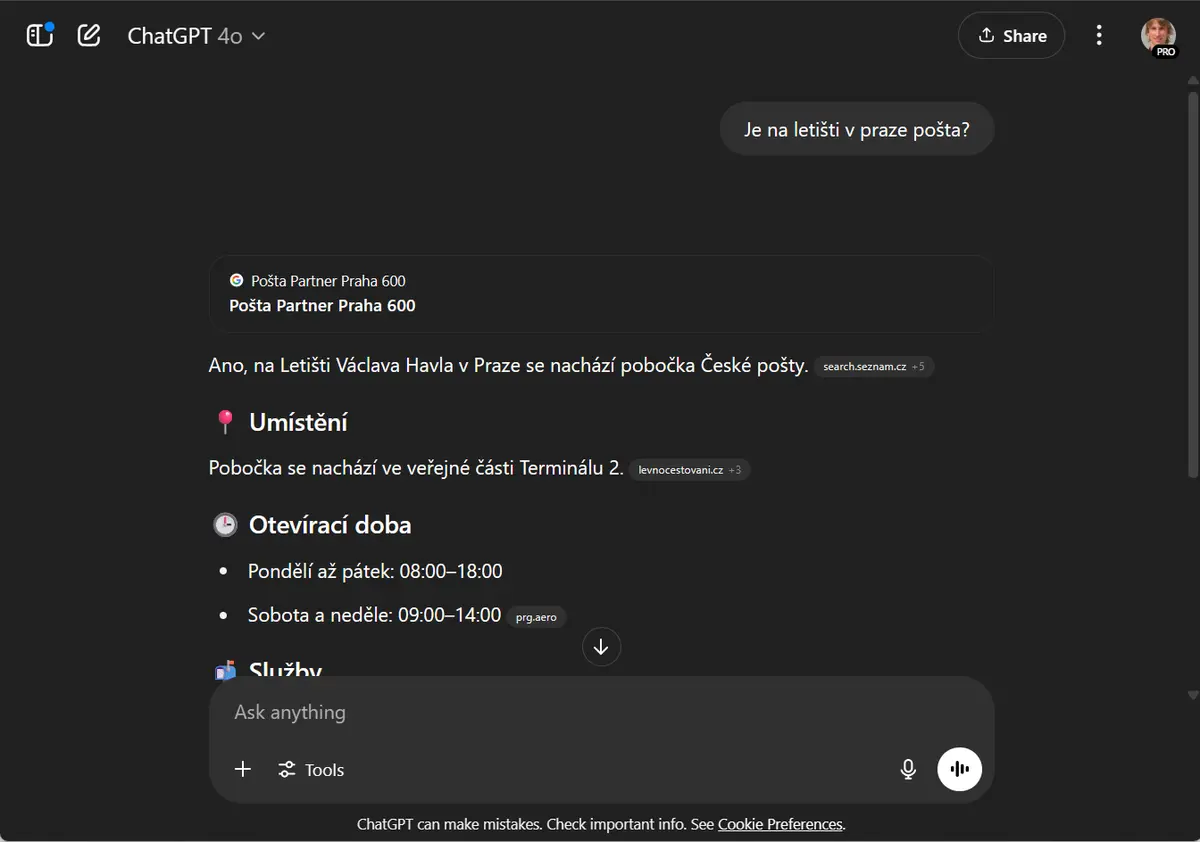
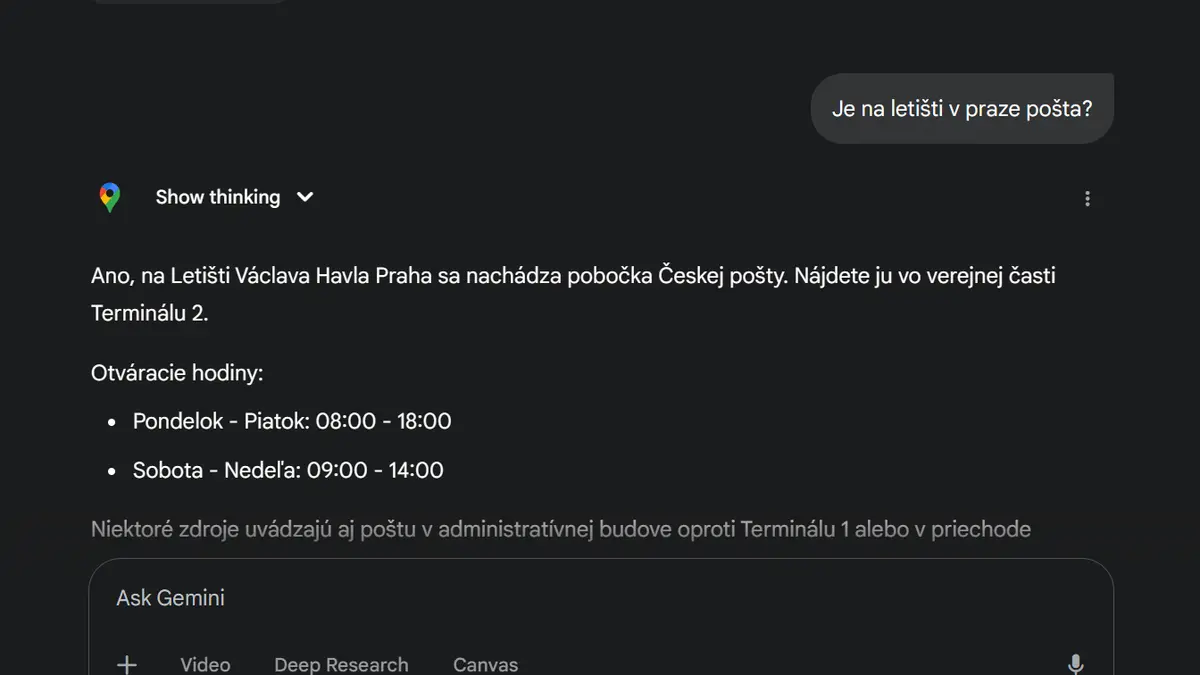
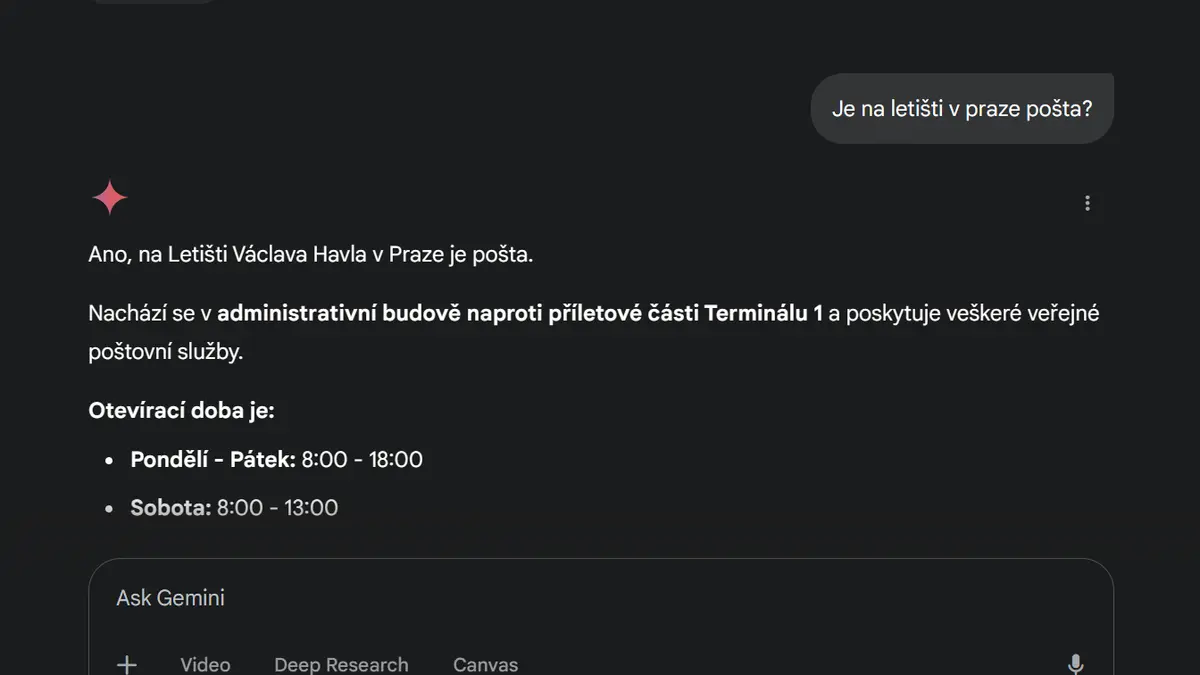
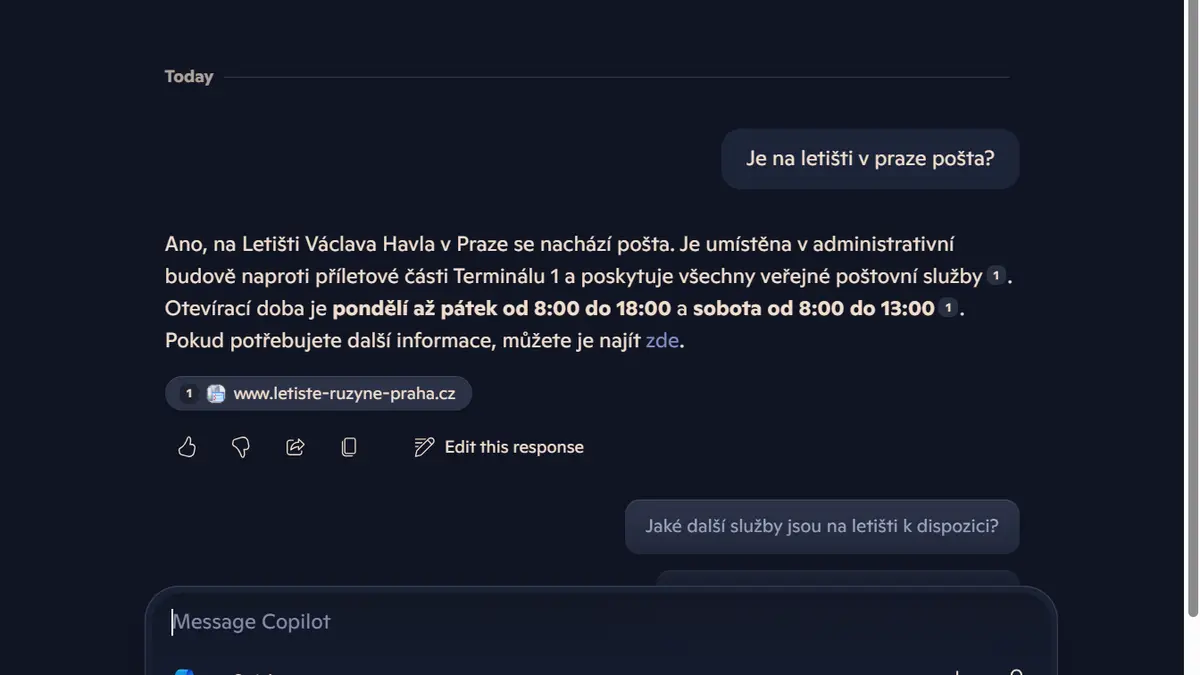
Ne že by byly všechny odpovědi úplně stejné. ChatGPT třeba ochotně popsal otevírací dobu a přidal své oblíbené smajlíky. Gemini byl z otázky tak nadšený, že z nějakého důvodu přepnul do slovenštiny. Grok mě chtěl potěšit a našel mi na letišti pobočky rovnou dvě, jednu z nich otevřenou 23 hodin denně. A Copilot mi kromě kladné odpovědi také nabídl odkaz na více informací.
Nejspíš už tušíte, v čem je háček. Na pražském letišti žádná otevřená pošta není. Ověřil jsem to za vás. Pobočka, která tam bývala, byla spolu se stovkami dalších poboček zavřena v roce 2023. Žádný z chatbotů ale tuto změnu nereflektoval. Jak je to možné? A proč o tom vůbec píšu?
Čemu se dá věřit?
Na internetu kolují zavádějící, špatné, chybné, nekvalitní nebo rovnou lživé informace. To není pro nikoho novinka. Nepravdy ostatně kolovaly informačním prostorem dávno před tím, než se současný web v laboratořích CERN zrodil. Lidé si proto za posledních pár tisíciletí vypěstovali řadu osvědčených metod, jak rychle posoudit, čemu mohou věřit a čemu ne.
První a nejjednodušší nástroj pro posouzení důvěryhodnosti byla osobní reputace daného člověka. Pokud někdo rozhlašoval věci, které se ukázaly jako nepravdivé, přišel o důvěru. Lidé si u jeho jména udělali mentální poznámku „pozor, kecá“ a nebrali jej od té doby moc vážně. Je to možná trochu zdlouhavé, ale pokud jste přišli do kontaktu jen s několika desítkami lidí, nebyl to až takový problém. Jakmile někdo důvěru svých známých zklamal, jen těžko ji získával zpátky.
S vynálezem písma, a především po nástupu knihtisku, ale došlo k odstranění časoprostorových omezení informace. Lidé mohli číst knihu mimo původní kontext, na druhé straně světa nebo třeba o desítky let později. Vyvstala tak potřeba posoudit informace od lidí, které jste v životě nikdy nepotkali.
Britský sociolog Anthony Giddens to nazývá rozklížením společenského systému: Interakce mezi lidmi už nebyly závislé na fyzických omezeních. Komunikace už nebyla vázaná na konkrétního člověka, konkrétní místo nebo daný kontext, jako tomu bylo v počátcích lidstva.
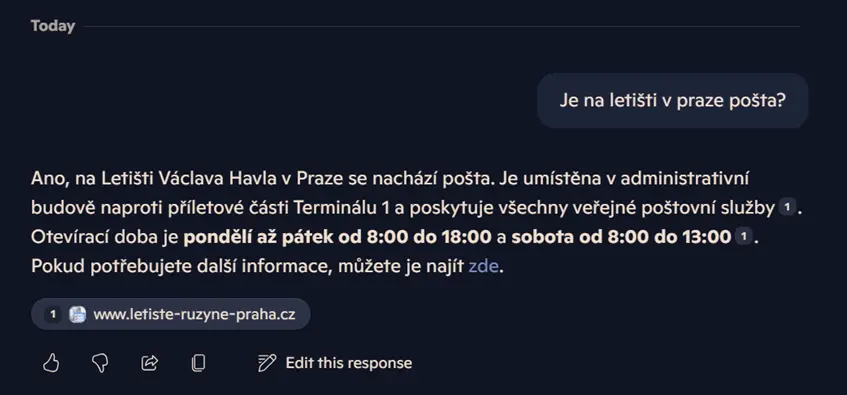
Výsledek vyhledávání přes Copilota.
Vylepšení komunikačních technologií podle komunikačního teoretika Harolda Innise odstartovalo rapidní rozvoj civilizace. Zároveň ale vyvstaly problémy s tím, jak mají tato sdělení – zachycená na papíře a dalších nových vymoženostech – lidé chápat a interpretovat. A jak se rozhodnout, čemu věřit.
Zprávy s rodokmenem
Jeden z nejlepších prostředků – doslova s tisíciletou tradicí – je pečlivé uvádění zdroje, ze kterého informace pochází. Je to vlastně rozšíření prapůvodního reputačního mechanismu: Když pracujete s informací od někoho jiného, měli byste zmínit, kdo to je. Čtenář se pak může sám rozhodnout, nakolik danému člověku věří.
Postupem staletí se tento intuitivní systém odkazování zdokonalil a formalizoval. Klíčovou roli sehrál třeba u zrodu moderního knihovnictví a především vědeckého bádání. Přiznat zdroje, ze kterých vycházíte, patřilo k dobrým intelektuálním mravům. „Pokud jsem dohlédl dále, bylo to proto, že jsem mohl stát na ramenou obrů,“ píše Isaac Newton v dopise z roku 1675. Vyzdvihuje tím důležitý aspekt moderní vědy: Není potřeba znovu vynalézat kolo. Když dobře pracujete se zdroji, můžete naskočit do jedoucího informačního vlaku a pokračovat v tom, co už prozkoumali lidé před vámi.
Odkazování zdroje není pro vědce jen nástroj na podrbání cizího ega. Když ve své studii odkazuji na výzkum někoho jiného, je v mém zájmu, aby byl tento původní výzkum snadno dohledatelný. Každá studie totiž obsahuje řadu „podružných“ detailů ohledně metod, sběru dat, technických detailů experimentů a dalších poznámek. Jednoznačným odkazem na zdroj se zabrání tomu, že by se tyto detaily postupně ztratily. Kdokoli chce, může si dle „rodokmenu“ každou informaci dohledat u původního zdroje.
To samé platí v novinařině. Když o něčem píšu, nejsem obvykle původním zdrojem informace. Dávám dohromady informace z více zdrojů, cituji experty, vědecké studie nebo zveřejněné statistiky. Je v mém zájmu, abyste přesně věděli, odkud čerpám. Můžete tak posoudit, jak jsou pro vás informace relevantní, nebo na moje zjištění navázat.
A pokud by se později ukázalo, že v některém ze zdrojů byla chyba, o to důležitější je vědět, kde k ní došlo. Zabrání se tomu, aby se můj článek stal zdrojem nepravdivé fámy. Kdokoli totiž i v budoucnu bude moci ověřit, zda jsou prameny stále relevantní, nebo zda je potřeba závěry přehodnotit.
Pračka špinavých informací
Samotný internet – přesněji webové stránky, World Wide Web – na tuto tradici informačního rodokmenu nejenže navázal, ale ještě ji prohloubil. Možnost odkazování zdrojů je klíčovou funkcí celého systému „pavučiny“, která navzájem spojuje různé internetové stránky. Jistě, ne každý na své zdroje odkazuje, ale díky principu řazení ve vyhledávačích se právě často odkazované stránky dostanou na oči více lidem.
Zdaleka ne všichni jsou ochotni rozkliknout zdroje informací. Ale důležité je, že je zdroj informace uvedený. Kdokoli se zájmem o hlubší prověření důvěryhodnosti tak může zkontrolovat původ dané informace.
Do tohoto prastarého systému ale současný trend chatbotů hází vidle. Generativní umělá inteligence – postavená na velkých jazykových modelech – dává odpovědi na základě toho, co na internetových textech natrénovala. Samotný model ale neví, kde se danou skutečnost dozvěděl. Nemá při generování k dispozici databázi původních textů. Místo toho sestavuje „pravděpodobnou odpověď“ s důrazem na užitečnost. Nebo alespoň zdání užitečnosti. Což je paradoxně právě ten problém.
Jazykový model nekopíruje existující texty, ale produkuje – slovo po slovu, token po tokenu – úplně nové věty. V tom je ostatně přidaná hodnota LLM. Databáze pro vyhledávání tady už byly dávno, ale teprve generativní AI umí na základě vašeho jedinečného kontextu vytvořit úplně nové texty.
Dřív si chatbot běžně vymýšlel zcela neexistující názvy a nikdy nepublikované knihy nebo kecal, že má přístup k aktuálnímu znění zákona. Tyto „halucinace“ umělé inteligence byly sice podivné, ale poměrně snadno odhalitelné.
Nemusíte číst, přečetl jsem za vás
V současnosti ale všechny hlavní modely „obohacují“ své odpovědi na naše zvědavé otázky o citace z reálných webových zdrojů. Tyto zdroje navíc více či méně zřetelně citují přímo v textu. Míra výskytu nejhorších omylů se tím radikálně snížila. Uživatelé tak snadno nabydou dojmu, že problém je odstraněn a výsledkům od chatbotu se už dá věřit.
A to je jádro současného problému. Informace přechroustané umělou inteligencí působí důvěryhodněji, než by si zasloužily. Chatbot totiž výsledek přizpůsobí na míru vaší otázce. Textu dodá profesionální formu, která na první pohled odpovídá perfektně ozdrojovanému dokumentu.
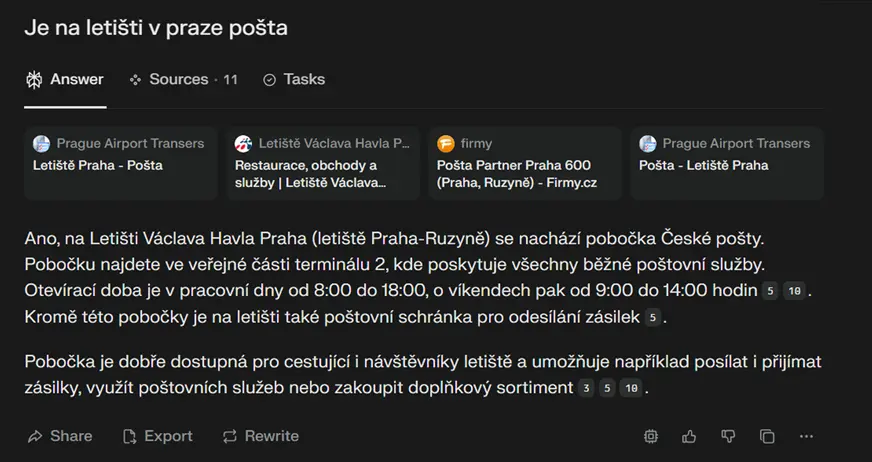
Chatbotový vyhledávač Perplexity si od začátku zakládá na tom, že svá tvrzení podpoří konkrétními citacemi a zdroji. Ale to je v tomto případě kámen úrazu.
Třeba vyhledávač Perplexity za nás prošel jedenáct zdrojů. Teoreticky byste tedy mohli každý z těch jedenácti odkázaných zdrojů otevřít. Ale proč byste to dělali, když to chatbot přečetl za vás?
Když jsme ještě na internetu hledali „postaru“, dostali jsme od vyhledávačů desítky odkazů. Posoudili jsme podle vnějších rysů, které zdroje nám přijdou věrohodné. Pak jsme na jednu nebo více těchto stránek klikli a pokusili jsme se v nich zorientovat. V úvahu jsme brali celou řadu věcí – grafiku celé stránky, pověst daného webu, dojem ze struktury textu, další odkazy, které vedou k dalším zdrojům…
Řadu těchto dojmů jsme získali zcela podvědomě. Asi jako když poprvé vejdete do restaurace. Aniž si to uvědomujete, posuzujete čistotu podlahy, profesionalitu personálu, chování ostatních strávníků a vůbec nasáváte atmosféru místa. Když uvidíte ušmudlané ubrusy, číšníka utírajícího si nos do dlaně nebo kouř linoucí se z kuchyně, otočíte se a půjdete jinam.
Představte si ale, že vám místo toho jídlo z této restaurace dovezou, zabalené a připravené v krabici. Najednou nemáte žádné signály, jak kvalitu restaurace předem posoudit. Přesně to dělá chatbot. Výsledky ze všech možných webů za vás přečetl a posoudil a vše vám přichystal, abyste nic nemuseli řešit.
Čímž se vracím k úvodní otázce tohoto článku: Jak vlastně chatboty dospěly k tomu, že je na pražském letišti otevřená pobočka pošty, nebo dokonce několik poboček? Když jsem postupně prošel zdroje, ze kterých tyto AI nástroje vycházely, nejčastěji se objevovala stránka s titulkem „Pošta na letišti Praha“ na doméně letiste-ruzyne-praha.cz.

Jak na vás působí tahle stránka? Já bych na ní aktuální informace rozhodně nečekal…
Kdybych viděl zastaralý vzhled tohoto neoficiálního webu, určitě bych se tam dlouho nezdržoval a šel bych pryč. Informacím na této stránce bych nepřikládal žádnou váhu. Jenže umělá inteligence mi podezřelý retro vzhled stránky zatají, respektive ukryje pod citaci. Navíc chatboty vycházely z desítky různých zdrojů, a tak skrze formální vzhled a srozumitelný jazyk vytvářejí dojem důvěryhodnosti.
Další problém nastává, když někdo takovou odpověď od chatbotu vezme a pošle dál. Typicky třeba zkopíruje text nebo vytvoří snímek obrazovky. Tím je definitivně přerušena jakákoli možnost výsledek zkontrolovat. Odkazy zmizí, a zůstává jen důvěryhodně znějící text od chatbotu.
Už dnes většina lidí nekliká na odkazy vedoucí na zdroj citací. Ale i kdyby někdo chtěl výsledky po chatbotu ověřit, nemá jak. Ve screenshotu není na co kliknout, a protože je text unikátní, pokaždé znovu na míru připravený, nelze odpověď ani nezávisle dohledat pomocí textové shody.
Oklikou jsme se vrátili do doby, kdy jsou informace vázané na mluvčího. Jen už to v řadě případů nebude člověk, ale chatbot. A výsledky, které nám dá, budou vypadat čím dál důvěryhodněji a přesvědčivěji. Dokážeme trvat na tom, že informaci „bez rodokmenu“ – tedy bez nezávisle ověřitelného zdroje – zásadně odmítáme? Nebo se postupně naučíme věřit souhrnům umělé inteligence a rádi zapomeneme, že jsme se někdy museli brodit informačními bažinami a sami rozhodovat, čemu se dá věřit?
Ještě nedávno jste mohli aspoň přibližně posoudit důvěryhodnost neznámého zdroje podle toho, kolik práce si někdo dal s vytvořením daného webu. Podrobnější web s větším množstvím aktuálních informací byl jako restaurace, kde je čisto a hostů je tam hodně. Ale tahle heuristika se rozpadá. Ani internetovým stránkám se skvělým designem a množstvím aktivních uživatelů se nedá věřit. Generativní umělá inteligence takových webů vytvoří desítky. Posuzování důvěryhodnosti se tak dále komplikuje.
Pryč jsou doby, kdy jsme mohli aspoň trochu věřit neznámým webovým stránkám. „Internet, jak jej známe, skončil,“ řekl mi před půl rokem mediální analytik Josef Šlerka. Umělá inteligence bude (možná už je) autorem většiny textů, které vznikají. Posoudit jejich důvěryhodnost bude čím dál těžší.

Možná tak budeme znovu primárně věřit konkrétním značkám, webům a lidem, které dlouhodobě známe. Opět bude záležet na tom, jakou si u nás vysloužili reputaci. Ostatní texty pak budeme muset považovat nejen za nedůvěryhodné, ale rovnou je podezírat z toho, že se nás aktivně snaží oklamat.
Já mohu aspoň dosvědčit, že pošta na pražském letišti otevřená není. Osobně jsem to ověřil za vás. Budete věřit mně, nebo dvanácti chatbotům, kteří sebevědomě tvrdí opak?
V plné verzi newsletteru TechMIX toho najdete ještě mnohem víc. Přihlaste se k odběru a budete ho dostávat každou středu přímo do své e-mailové schránky.





