






Článek
Po ruské invazi nastal v Evropě rychlý a masivní přesun obyvatelstva. Do Česka již dorazilo přes čtvrt milionu uprchlíků z Ukrajiny. Řada Čechů jim chce pomoci a narážejí při tom na jazykovou bariéru. Přestože je totiž ukrajinština slovanský jazyk, její psaná podoba používá cyrilici, která je latince podobná jen vzdáleně.
Můžete ale využít nástroje, které se postarají nejen o přepis cyrilice do latinky, ale o kompletní překlad textu. A to nejen jednotlivých slov, ale i celých vět. Nově je pro překlad k dispozici ukrajinsko-český překladač LINDAT.

Do webové stránky stačí napsat slova či věty. Překladač zadaný text automaticky přeloží do druhého jazyka. Nabídne i transkripci do latinky a cyrilice, aby byl výstup srozumitelný pro obě strany dialogu. Jednoduché rozhraní vyvinuli dobrovolníci v rámci víkendového hackathonu.
„Asi pět dní po invazi jsme se rozhodli, že chceme Ukrajincům nějak pomoci,“ popisuje vývojář Michal Novák z Ústavu formální a aplikované lingvistiky Matematicko-fyzikální faulkty Univerzity Karlovy. Od první myšlenky k veřejně dostupnému překladači uplynula překvapivě krátká doba. „Do té doby jsme ukrajinský překladač vůbec neměli.“
Jak mohl překladač vzniknout tak rychle? „Měli jsme ale na co navázat,“ vysvětluje Novák. Využití algoritmů strojového učení vysvětluje, jak mohl univerzitní tým za pouhé dva týdny vyvinout funkční službu. A pochopení principu strojového učení také pomůže pochopit, proč dělá nový překladač opravdu zvláštní chyby, kterých by se lidský překladatel nikdy nedopustil.
Trénovaní na motivačních videích nebo Wikipedii
Překladač LINDAT je založený na principu učení neuronových sítí. Konkrétně na systému, který vyvinuli čeští vědci z „matfyzu“ již před několika lety. V roce 2020 o svém algoritmu publikovali článek v prestižním vědeckém časopise Nature, jejich systém CUBBITT totiž dosahoval u anglicko-českých překladů lepších výsledků než světově nejznámější překladač Google Translate a v něčem dokonce překonával i lidské překladatele. Takže základ nového překladače byl nadějný.
„Ukrajinsko-český překladač je trénován přesně stejným způsobem jako anglicko-český CUBBITT. Liší se jen trénovací data,“ potvrdil nám Martin Popel, hlavní autor zmíněného článku. Nová anglicko-česká verze ale už podle něj umí zohledňovat kontext celého překládaného dokumentu. To zatím nově vzniklý ukrajinský překladač nedělá. Bere v potaz jen obsah jednotlivých vět. Důvodem je nedostatečný počet trénovacích dat.
Neuronovou síť jsme trénovali na filmových a seriálových titulcích, na přeložené beletrii, článcích z Wikipedie nebo TED Talks.
Neuronová síť se totiž učí na základě dat, která dostane k dispozici. V případě překladačů je tedy ideální „nakrmit neuronku“ texty, které jsou již lidmi přeložené. A ideálně přeložené strukturovaně tak, aby si jednotlivé věty vzájemně odpovídaly. Čím více dat a čím jsou kvalitnější a lépe strukturovaná, tím lépe.
„Sháněli jsme na internetu, co se dalo,“ popsal první den práce Jindřich Libovický, další z týmu vývojářů ÚFAL. „Velkou část zdrojových dat tvoří filmové a seriálové titulky a wikipedické články. Od Filozofické fakulty UK jsme dostali přeloženou beletrii. Využili jsme také volně dostupné překlady uživatelských rozhraní (UX) nebo titulky k motivačním přednáškám TED Talks.“ Celkově šlo podle tvůrců o miliony textů, které byly k dispozici v češtině i ukrajinštině.
Strojové učení a neuronové sítě
Strojové učení funguje na principu analýzy velkého množství dat. Počítačové programy jsou sadou instrukcí a podle těchto instrukcí zpracovávají předložená data. Strojové učení umožňuje nový přístup k řešení problémů počítačem. Než aby programátor počítači napsal veškeré instrukce pro všechny eventuality jednotlivě, tak naprogramuje způsob, kterým se počítač sám učí na dodaných „trénovacích“ datech. Učení probíhá pomocí sítí samostatných programů, tzv. umělých neuronů, proto se systému říká neuronová síť.
Například v případě strojového překladu se počítač trénuje na velkém množství textů, které jsou dostupné v angličtině i češtině. Neuronová síť zkouší překládat části textu a poté zkontroluje, nakolik se její verze liší od té správné. Ty části neuronů, jež napovídaly správnou možnost, budou posíleny a příště budou hrát v rozhodování větší roli. Čím rozsáhlejší a kvalitnější jsou vstupní data, tím lepší může být výsledek.
Pro rychlejší trénování využili vývojáři i chytrý trik, který není v oblasti strojového učení neobvyklý. Částečně vytrénovaný překladač totiž může sám sebe zlepšovat i bez použití strukturovaných a přeložených dat: „Překladač si například sám přeloží českou větu do ukrajinštiny. A pak otočíme ten směr a tahle data použijeme pro natrénování překladu z ukrajinštiny do češtiny,“ vysvětluje Libovický. „Na vstupu tedy je možná ne moc dobrá ukrajinština, ale na výstupu je kvalitní čeština. A na tom se neuronová síť může trénovat. Dokonce to tomu překladači trochu pomůže, bude pak robustnější a poradí si i s chybnými vstupy.“
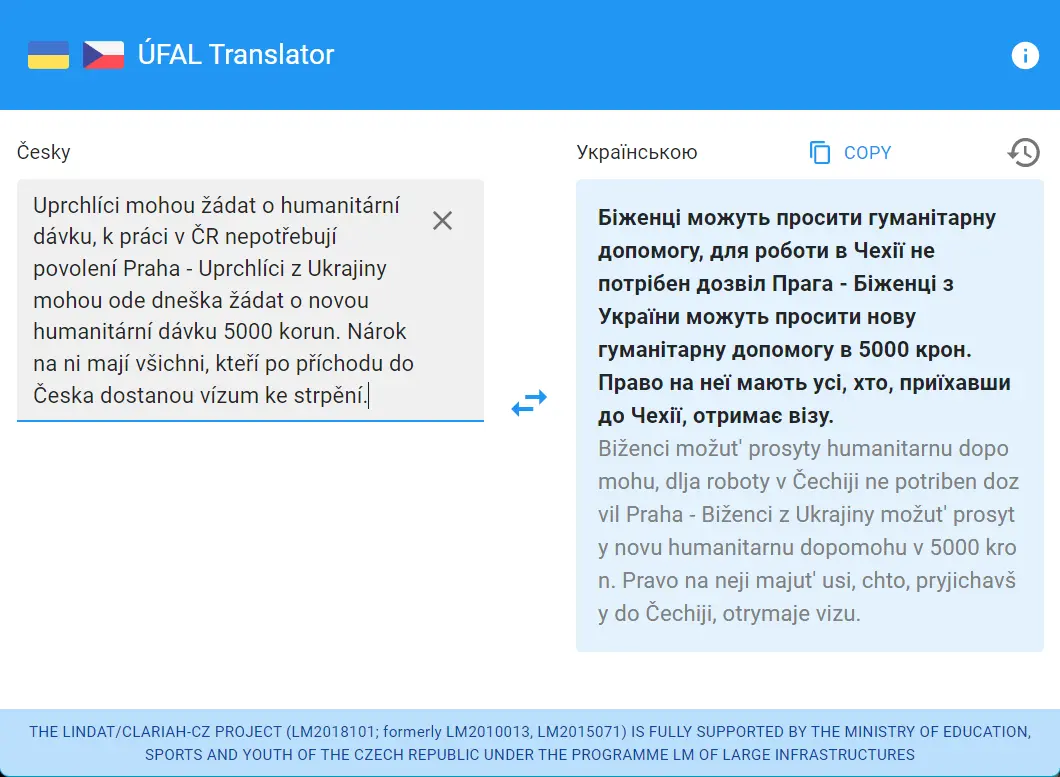
Překladač je schopen překládat celé věty. V rámci delšího souvětí je obvykle schopen zachovat srozumitelnost a kontext.
Celkově šel vývoj i díky dobré dostupnosti přeložených textů velmi rychle. „Měli jsme štěstí. Hned druhý den jsme našli dostatek paralelních dat na internetu,“ libuje si Jindřich Helcl, třetí z týmu vývojářů (jádro týmu tvoří šest lidí, další pomáhají externě). „To není úplně běžné. U některých jazykových párů vůbec žádná paralelní data nejsou.“
Legrační chyby nejde rychle odstranit
Přestože je překladač zatím ve fázi vývoje, dává již velmi dobré výsledky. Vývojáři nechali několik textů ohodnotit lidským překladatelům. Profesionálově nový systém srovnávali s nyní dostupným Google Translate a také lidským překladem. „Ve směru do češtiny bychom měli být výrazně lepší, než Google Translate,“ věří Libovický. „Manuální evaluace vyšla tak, že Google dostal v průměru 7,4 hvězdiček a náš překladač 8,3 hvězdiček.“ Lidmi přeložené věty byly ale hodnoceny ještě lépe.
Kolega z redakce Seznam Zpráv, který mluví česky i ukrajinsky, hodnotil překladač Lindat na základě prvních dojmů jako povedený: „Na úrovni konkrétních slov překládá v některých případech o něco lépe, než Google Translate. Naopak překladač od Googlu překládá méně doslovně a více přirozeně,“ míní Konstantin Sulimenko, moderátor podcastu Trafika. Oba strojové překladače pak podle něj trpí problémy s kolísáním mužského a ženského rodu: „Trochu to stěžuje orientaci v přeloženém textu,“ všímá si Sulimenko.
Vývojáři překladače LINDAT ostatně upozorňují, že systém zdaleka není dokonalý: „Nemůžeme se zaručit za výstupy, které z toho lezou,“ varuje Helcl. „Model může občas generovat nadávky, rasové a kulturní stereotypy, které nejsou vhodné a my to tam nechceme.“ To je u podobných systémů, které generují text na základě dat z internetu, bohužel poměrně obvyklé. Slavný je případ z roku 2016, kdy se neuronová síť od Microsoftu naučila od uživatelů na Twitteru rasistické nadávky.
A tyto chyby nelze jen tak odstranit. Model totiž vychází z použitých dat, na kterých byl natrénován. „Použili jsme desítky milionů podkladů, je těžké mít vše pod kontrolou,“ přiznává Novák. „Když na problém narazíme, tak se jej pokusíme vyhledat a odstranit.“
Pak je ale potřeba model znovu přetrénovat, což může trvat týden nebo i déle. „To uživatelům nejspíš někdy nedochází,“ uvědomuje si Novák „Mají možná pocit, že když to překládá Jihlavu jako Žitomyr, tak prostě někde opravíme záznam v databázi a bude to v pořádku. Ale ta oprava klidně může trvat i týden nebo dva týdny.“
Právě špatné překlady místních názvů měst působí v jinak dobrých překladech jako „pěst na oko“. Při testování jsme našli desítky případů, kdy je české město přeloženo jako město na Ukrajině.
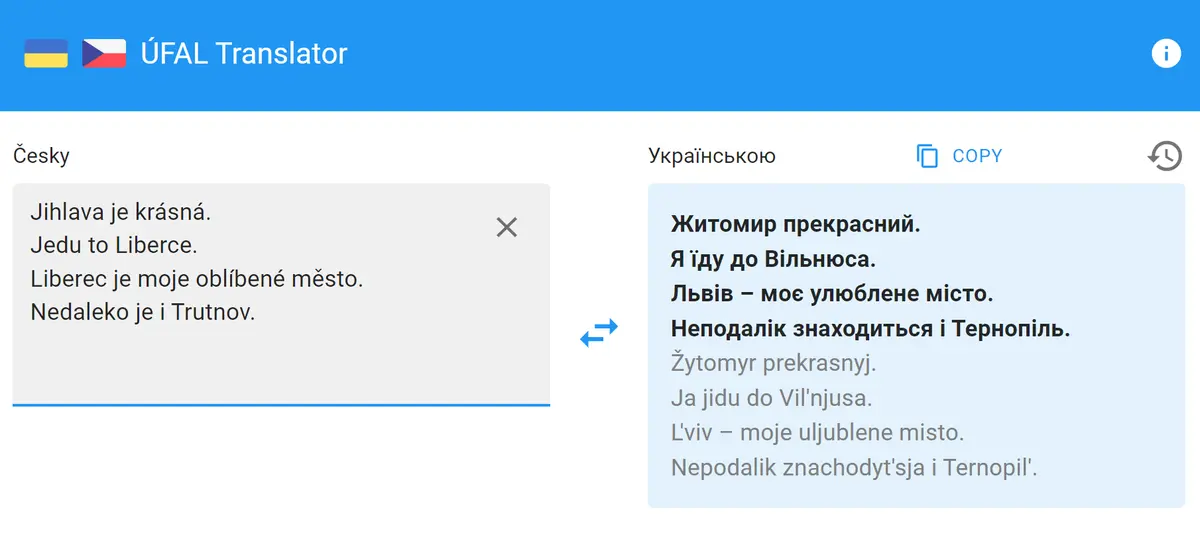
Z Jihlavy udělal překladač ukrajinský Žitomir, z Liberce je podle kontextu věty litevský Vilnius nebo ukrajinský Lviv a z Trutnova je západoukrajinský Ternopil.
Vývojáři o chybě vědí a pracují na jejím odstranění. Jak ale již zaznělo, nemohou zkrátka změnit pár záznamů v databázi. Musejí najít, jak chyba vznikla. Podezírají, že za to mohou některé špatně spárované věty.
Neuronová síť nehledá slova ve slovníku. Na základě trénovacích dat napodobuje rozhodnutí, která dělají lidští překladatelé.
„Hodně lidí si myslí, že je to slovník,“ popisuje častý omyl Helcl. "Ve slovníku si najdeme jedno slovo a napíšeme jeho překlad. Ale náš překladač nepřekládá slovo po slově. Místo toho se učí napodobovat rozhodovací proces lidských překladatelů. Informace ze vstupní věty se použijí na generování výstupní věty, aniž by to sledovalo nějaká jasně daná pravidla.
Na co je strojový překlad vhodný? Co zvládne lépe člověk?
Automatický překlad exceluje při překládání textů administrativního charakteru, akademických studií, zpravodajství… „Čím menší míra kreativity a čím stereotypnější vyjadřování, tím spolehlivější automatický překlad je,“ všímá si český překladatel Viktor Janiš. Stačí také všude tam, kde lidé chtěli jen porozumět nějakému textu v cizím jazyce a nejde jim o 100% výsledek.
A na co se naopak neuronové sítě (zatím) nehodí? „Obecně lze říct, že mívají problém s intertextualitou, ironií, se všemi situacemi, kdy daný jev v cílovém jazyce neexistuje, takže je třeba zvolit vhodný opis. Neumí vhodně zvolit tykání či vykání, poznat pohlaví mluvčího, odstínit sílu vulgarit či najít správnou míru hovorovosti,“ vyjmenoval Janiš v rámci srovnání technologií překladačů v článku Seznam Zpráv. „A zákonitě naprosto selhávají, když je daná pasáž přeložitelná jen tvůrčím způsobem, tedy se značným autorským vkladem. Neumí kompenzovat, překládat slovní hříčky či vtipy a samozřejmě neumí překládat poezii. Ta bude podle mě poslední nedobytnou baštou.“
Při prvním použití překladače můžete zvolit, zda mohou výzkumníci vaše texty uložit a využít pro další zlepšení. Zatím nebyl na hlubší analýzu čas, ale podle prvních záznamů se zdá, že lidé nejčastěji používají překladač na koordinaci cestování nebo k setkání na nádraží. O důvod více zkontrolovat si před odesláním, zda neuronová síť náhodou nevytvořila z vašeho poklidného městečka ostřelované předměstí Kyjeva.
A také si ověřte, že do překladače skutečně vkládáte správný jazyk. „Už jsme také dostali upozornění, že náš překladač na nějakou větu vůbec nefunguje,“ vzpomíná Novák. „A pak se ukázalo, že tam lidé nevkládali text ukrajinský, ale ruský.“
Oprava: Opravili jsme překlep v příjmení jednoho z vývojářů.





