





Článek
Na světě lidé sice mluví několika tisícovkami jazyků, většina textů na internetu je ale napsána v angličtině (přes 61 %). Následuje ruština, španělština, turečtina, němčina… Čeština je v žebříčku „internetových jazyků“ na krásném 22. místě. I díky tomu tak existují velmi dobré nástroje na strojový překlad z a do češtiny.

Naopak jazyky, které nejsou v digitálním prostředí často používány, jsou z hlediska automatického překladu těžko uchopitelné. Chybí totiž data, na kterých by se mohlo strojové učení trénovat. To znamená, že asi pětina světové populace nemá k dispozici strojový překlad pro svůj hlavní jazyk.
Změnit to chce společnost Meta, provozovatel sítí Facebook, Instagram a WhatsApp. Před půl rokem oznámili svou iniciativu Žádný jazyk nezapadne (No Language Left Behind) a nyní zveřejnili svůj dílčí výsledek: systém schopný překládat mezi více než 200 jazyky.
„Právě jsme zpřístupnili model strojového učení, který dokáže překládat z 200 různých jazyků,“ pochlubil se na facebooku Mark Zuckerberg, šéf společnosti Meta. „Mnohé z těchto jazyků přitom současné překladatelské systémy zatím nepodporovaly. Techniky modelování AI (umělé inteligence), které jsme použili, pomáhají vytvářet vysoce kvalitní překlady pro jazyky, kterými mluví miliardy lidí na celém světě.“
Afrika je dlouhodobě přehlížená
Trénování neuronové sítě pro překládání není v současné době vůbec neobvyklé. Když máte zkušenosti a dostatek zdrojových dat, můžete přidat novou řeč velmi rychle, jak nedávno ukázal třeba český tým při tvorbě překladače česko-ukrajinského. Učí se především z webových stránek, knih a dalších textů, které jsou k dispozici v obou jazycích.
Jenže pro řadu jazyků taková data nejsou k dispozici. Výzkumníci Meta takové jazyky nazývají „málo zastoupené“ (low-resource languages). Jsou to třeba desítky afrických jazyků, které nejsou příliš zastoupeny v digitálním světě.
„Co můžeme udělat k tomu, abychom zdvojnásobili počet jazyků, ze kterých jde strojově překládat?“ ptají se výzkumníci v nově publikované studii. „A jak vytvořit nástroj na plynulý překlad, který zachová význam vět, i v těchto málo používaných jazycích?“
Výzkumníci zkombinovali několik postupů. Především sehnali 44 lidí z celého světa, kteří mluví některými z málo zastoupených jazyků, především z Afriky a Jižní Ameriky. S nimi vedli rozsáhlé strukturované rozhovory s cílem zjistit, kde je největší potřeba pro strojový překlad a jaké jsou potenciální výzvy. Řada z nich vyjádřila obavu z toho, že jazyk, který není zastoupen v digitálním světě, bude postupně upadat, protože velké platformy logicky dávají prioritu rozšířeným jazykům, především angličtině. Za to je ostatně Facebook dlouhodobě kritizován.
Na zákadě těchto rozhovorů i na základě rešerší jazyků používaných na internetu sestavili výzkumníci seznam 200 jazyků, do kterých se jejich nástroj „zakousne“. Z toho 66 jazyků bylo nových, tedy takových, že je dosud neumí překládat Google Translate ani překladač firmy Microsoft. Velká část těchto nových jazyků je zastoupená v Africe, jejíž populace byla v současných systémech strojového překladu zastoupena relativně nejméně.
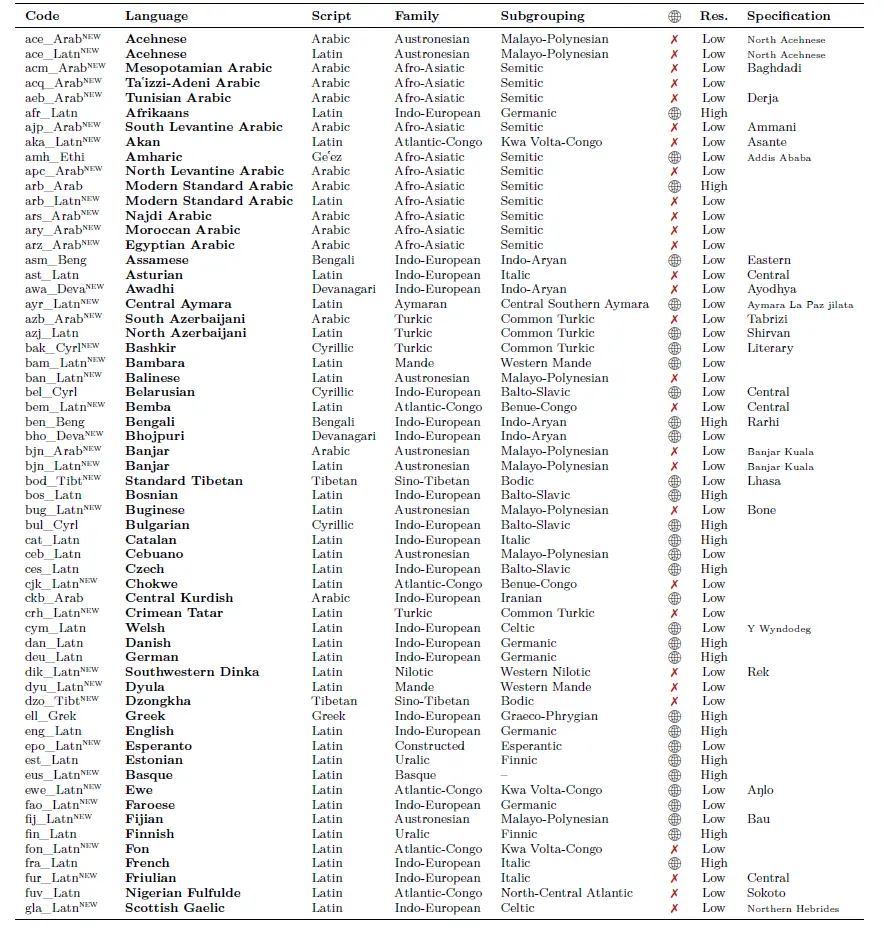
Ukázka některých jazyků zahrnutých do nového modelu NLLB-200.
Z málo zastoupených evropských jazyků je v nabídce třeba benátština nebo skotská gaelština.
Nejtěžší bylo sehnat data
Tým využil kromě dostupných textových dat také služeb profesionálních překladačů. Zatímco u jazyků jako angličtina bylo k dispozici až příliš textů, pro jiné jazyky bylo potřeba tréninková data rozšířit. Nezávisle na nich pak další tým lidských expertů tyto překlady hodnotil a případně opravoval.
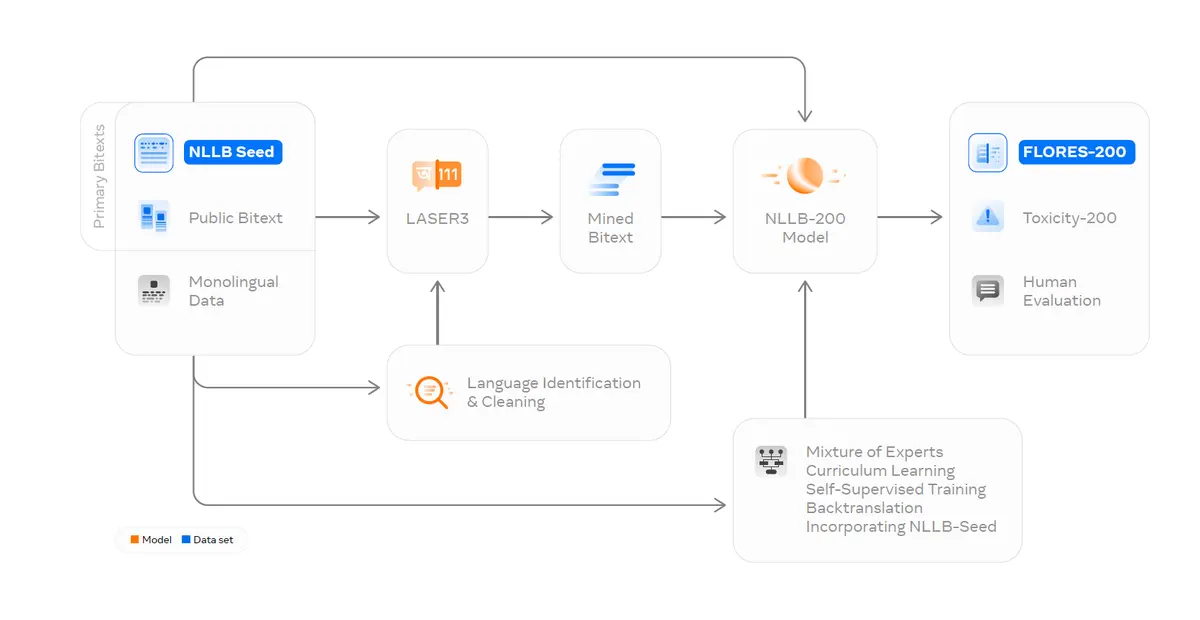
Lidmi přeložené věty tvoří jen jednu část trénování, slouží především k validaci vytrénovaného modelu NLLB-200.
Výsledkem je dataset FLORES-200, který se skládá ze tří tisíců anglických vět přeložených do všech dvou set jazyků. Ten je veřejně k dispozici a může posloužit například k ověřování dalších překladových systémů.
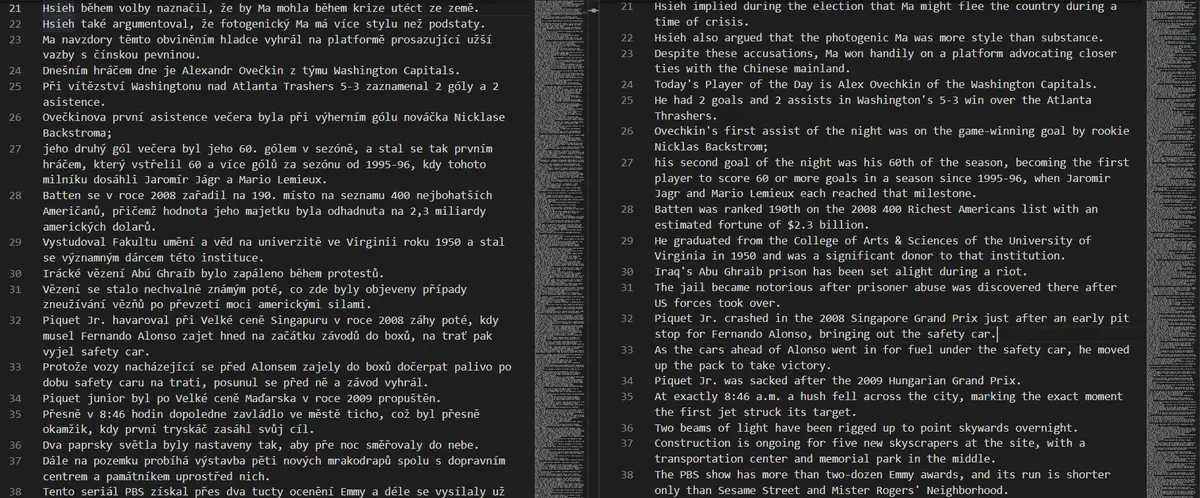
Ukázka profesionálně přeložených vět, vlevo český překlad, vpravo anglický originál.
Hlavním zdrojem trénovacích dat je „těžba dat“ z internetu. Model NLLB-200 k trénování využívá i data dostupná jen v jednom jazyce, které ale lze využít na nácvik struktury jazyka. Facebook využívá data z velkých dostupných datasetů CommonCrawl a ParaCrawl, ve kterých detekuje použitý jazyk.
„Zpracovali jsme přibližně 37,7 petabajtů dat,“ uvedli výzkumníci. „To byla výzva z hlediska úložného prostoru i správy dat. Zejména jsme museli činit těžká rozhodnutí při filtrování jazyků s vysokým počtem zdrojů a využili jsme pouze asi 30 % dat u těch nejvíce zastoupených jazyků.“
Pro trénování neuronových sítí určených ke strojovému překladu jsou klíčová taková data, která jsou dostupná alespoň ve dvou jazycích (tzv. bitexty, tedy jazykové páry). Nejčastěji jsou taková data dostupná v párové kombinaci s angličtinou, protože do této novodobé lingua franca (celosvětového jazyka) jsou obvykle nejčastěji překládány lokální informace. Tým výzkumníků Meta také využil křesťanskou Bibli nebo testy nadnárodních organizací, které jsou rovněž přeloženy do většiny jazyků světa.
Všechny jazyky naráz
Výsledná neuronová síť NLLB-200 zahrnuje, jak již název napovídá, 200 jazyků a umí překládat z každého jednotlivého jazyka do jakéhokoli dalšího, oběma směry. To dohromady znamená přes 40 tisíc kombinací jazykových párů. Proto je užitečné, že se model nemusí trénovat pro každou dvojici zvlášť.
Naopak, nastává zajímavá situace, kdy se neuronová síť může naučit překládat lépe z jednoho jazyka do druhého díky zdánlivě nesouvisejícím datům v úplně jiném jazyce: „Jindy je to celkem nečekané. Třeba překlad z polštiny se zlepšil, když jsme využili data získaná trénováním umělé inteligence na textech ve vietnamštině nebo thajštině,“ popsal mi tento neintuitivní jev v roce 2017 Barak Turovsky, který vyvíjel neuronový překlad pro Google Translate. „Je to tak trochu černá skříňka.“
Strojové učení a neuronové sítě
Strojové učení funguje na principu analýzy velkého množství dat. Počítačové programy jsou sadou instrukcí a podle těchto instrukcí zpracovávají předložená data. Strojové učení umožňuje nový přístup k řešení problémů počítačem. Než aby programátor počítači napsal veškeré instrukce pro všechny eventuality jednotlivě, tak naprogramuje způsob, kterým se počítač sám učí na dodaných „trénovacích“ datech. Učení probíhá pomocí sítí samostatných programů, tzv. umělých neuronů, proto se systému říká neuronová síť.
Například v případě strojového překladu se počítač trénuje na velkém množství textů, které jsou dostupné v angličtině i češtině. Neuronová síť zkouší překládat části textu a poté zkontroluje, nakolik se její verze liší od té správné. Ty části neuronů, jež napovídaly správnou možnost, budou posíleny a příště budou hrát v rozhodování větší roli. Čím rozsáhlejší a kvalitnější jsou vstupní data, tím lepší může být výsledek.
Výzkumníci Meta vyzkoušeli několik různých metod, aby zabránili tomu, že by velké jazyky ve výsledném modelu „převálcovaly“ ty menší. Průběžně pracovali s neuronovými sítěmi, které měly 250 milionů parametrů, později 1,3 miliardy parametrů nebo 3,3 miliardy parametrů.
„Nejprve jsme vyvinuli sítě typu směs odborníků (mixture-of-experts networks), které mají sdílenou a specializovanou kapacitu, takže jazyky s malým množstvím zdrojů bez velkého množství dat mohou být automaticky přesměrovány na sdílenou kapacitu,“ uvedli výzkumníci na blogu. „To v kombinaci s lépe navrženými regularizačními systémy zabraňuje nadměrnému přizpůsobování (tzv. overfitting). Rovněž jsme postupovali podle dvoukrokového učebního přístupu, kdy jsme nejprve několik generací trénovali jazyky s velkým množstvím zdrojů a teprve poté jsme zavedli dvojice jazyků s malým množstvím zdrojů, což opět snížilo problém s overfittingem.“
Výsledná neuronová síť pracuje s 54 miliardami parametrů a k jejímu vytrénování použili vědci jeden z nejvýkonnějších superpočítačů na světě, AI Research SuperCluster využívající tisíců grafických karet.

Superpočítač AI Research SuperCluster společnosti Meta byl postaven začátkem roku 2022 a firma plánuje jej nadále rozšiřovat.
Vytrénovanou neuronovou síť pak výzkumníci nadále testovali, například proto, aby zjistili, zda při překladech nedochází ke změně významu nebo ke generování nechtěného nenávistného obsahu. „Toho jsme dosáhli vytvořením seznamů vulgárních výrazů pro všechny podporované jazyky, abychom mohli odhalit a odfiltrovat vulgaritu a další potenciálně urážlivý obsah. Zveřejňujeme seznamy hodnocení toxicity a srovnávací testy pro všech 200 jazyků, abychom ostatním výzkumníkům poskytli nástroje ke snížení rizik v jejich modelech. Abychom se ujistili, že naše úsilí rozšiřujeme zodpovědným způsobem, spolupracujeme s interdisciplinárním týmem, který zahrnuje lingvisty, sociology a etiky, abychom se dozvěděli více o každém z jazyků, o nichž uvažujeme.“
K dispozici všem?
Výsledná síť NLLB-200 umí překládat dvakrát více jazyků než předchozí modely zahrnující „pouze“ sto jazyků. Přesto – nebo možná proto – se zároveň zvedla i úroveň překladů, kterou výzkumníci měří pomocí tzv. BLEU skóre pro posuzování přesnosti přeložených vět.
Posoudit kvalitu překladu ale není úplně jednoduché, hlavně u nových jazyků: „Jedním ze zajímavých jevů je, že lidé, kteří hovoří málo zastoupeným jazykem, mají často nižší nároky na kvalitu překladu, protože nemají žádný jiný nástroj, se kterým by to srovnali,“ říká výzkumnice Angela Fan z týmu Meta. „Jsou velmi velkorysí, a tak jim musíme znovu připomínat, podívejte se, musíte být přísnější, a pokud uvidíte chybu, upozorněte nás na ni.“
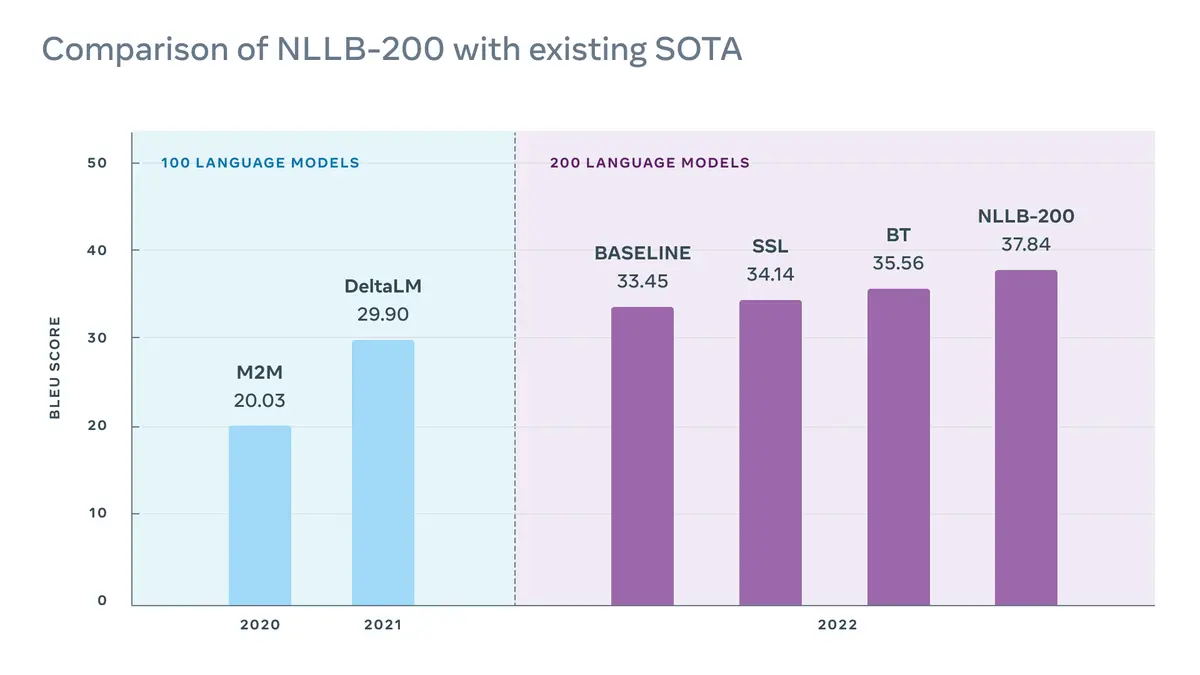
Napříč jazyky si síť NLLB-200 udržela překvapivě vysoké skóre 37 bodů. Za „srozumitelný překlad“ se obvykle považují hodnoty nad 30 bodů škály BLEU.
„Na první pohled se mi nezdá, že by bylo na tomto modelu něco přelomového po vědecké stránce,“ napsal mi český vývojář Tomáš Mikolov, který se na neuronové sítě specializuje a jehož výzkum vědci z Meta v článku o NLLB-200 hned několikrát citují. „Jde o inkrementální práci. Kombinují to, co už známe, a rozšiřují trénovací data. To samé by mohli klidně udělat i firmy Google nebo Microsoft, pokud by na takovou věc chtěly dát peníze.“ V praxi to podle Mikolova samozřejmě může být užitečný nástroj pro jazyky, ke kterým zatím strojový překlad nebyl k dispozici.
NLLB zatím není on-line ve formě veřejně přístupného nástroje, zájemci mohou kvalitu překladu posoudit na vybraných knihách. Výzkumníci k prezentaci vybrali pohádky a příběhy právě v jazycích, které dosud nebyly v systémech pro strojový překlad zastoupeny.
Společnost Meta v poslední době zásobuje komunitu vývojářů velkým množství dárků. V květnu zveřejnila datové sady k trénování svého modelu pro generování anglických textů s cílem „demokratizovat velké jazykové modely“. A také nástroj pro překládání 200 jazyků je uvolněn pod licencí open source.
„Abychom pomohli dalším výzkumníkům zlepšit jejich překladatelské nástroje a navázat na naši práci, zpřístupňujeme vývojářům modely NLLB-200 a datovou sadu FLORES-200,“ uvádí tisková zpráva Meta. „Navíce zveřejňujeme náš kód pro trénování modelů a kód pro vytvoření tréninkové datové sady.“
Zatím jsme neměli možnost vyzkoušet překlad v praxi. Brzy by ale měli mít tento nástroj k dispozici třeba přispěvatelé do internetové encyklopedie Wikipedia, což je jeden z mála projektů se skutečně velkým jazykovým záběrem. V současné době nabízí Wikipedia obsah ve 327 jazycích. Strojové učení už nyní zvládne překlad mezi dvěma stovkami z nich.







