






Článek
Analýzu si také můžete poslechnout v audioverzi.
Kolik lidí žilo v Olomouci v roce 1921? Správně bychom se měli samozřejmě podívat do archivů, kde najdeme oficiální statistiky. Co kdybychom se ale místo toho zeptali chatbota? Bez zaváhání odpoví. Jenže pokaždé trochu jinak…
Podle oficiálních statistik žilo v roce 1921 v Olomouci 66 tisíc obyvatel (některé zdroje uvádějí 57 tisíc). Nejenže se chatbot moc netrefil. Když si projdete několik odpovědí, zjistíte, že nám pokaždé hodil trochu jiné číslo. A zároveň si k tomu číslu obvykle vymyslel omáčku okolo, přidal zdroje nebo smyšlené detaily. Proč?
Kdybychom chatbotovi dali přístup na web, zkusil by si napřed odpověď vyhledat. Ale když umělá inteligence nemá přístup na internet nebo když odpověď nenajde, tak se nezalekne.
Nečerpá odpovědi z nějaké databáze. Místo toho na základě svého tréninku odhaduje, co zní pravděpodobně. Sebevědomě (chtělo by se říci drze) tak generuje text, který na první pohled vypadá věrohodně. „Tyto systémy jsou navržené tak, aby si vymýšlely. To je podstata jejich fungování,“ zdůrazňuje Emily Benderová, profesorka lingvistiky z University of Washington. „To není chyba, která by šla opravit. To je klíčový aspekt této nové technologie.“
Ostuda pro výzkumníky, firmy i právníky
Většina vědců má radost, když někdo cituje jejich studii. Ale americká epidemioložka Katherine Keyesová potěšena nebyla. Ne proto, že se na ni odkazovala poměrně kontroverzní studie amerického ministerstva zdravotnictví. Ale proto, že citovanou studii v životě nenapsala. Ona, ani nikdo jiný.
„Citovaný článek není skutečným článkem, na kterém jsem se já, nebo moji kolegové podíleli,“ vysvětlila novinářům. „Na podobné téma jsem články skutečně psala, ale ne do tohoto časopisu a s tímto týmem.“ Podobných chyb bylo v ministerském dokumentu více: odkazy na neexistující, leč reálně znějící studie.

Citace, kterou si chatbot vymyslel, obsahuje i smyšlenou webovou adresu, název skutečného vědeckého časopisu a další formální náležitosti. Na první pohled je k nerozeznání od odkazů na existující literaturu.
Mluvčí Bílého domu to svedla na „problémy s formátováním“. Každý, kdo ale poslední tři roky nežil v jeskyni, ale okamžitě uhodl skutečný důvod: autoři na ministerstvu si usnadnili práci a zapojili do tvorby ChatGPT.
Tento slavný chatbot od OpenAI koncem roku 2022 odstartoval masivní vlnu zájmu o generativní umělou inteligenci. Nemine týden, abychom nečetli o tom, co všechno AI už dokáže: zkoumá tajemství života, překonává špičkové programátory, diagnostikuje lépe než lékaři a brousí si zuby na ty nejkomplikovanější úkoly.
Tak proč pořád – a toto je terminus technicus – tak kecá? Proč se právníci musejí omlouvat za to, že citovali neexistující spisy, aerolinky za neexistující slevy a novináři za zkomolené jméno?
Firmy se podle výzkumu McKinsey zdráhají nasazovat umělou inteligenci nejčastěji právě proto, že se na výstup nemohou spolehnout. Nabízí se logická otázka: Když je ta umělá inteligence tak inteligentní, proč si vymýšlí?
Skládání snů, slůvko po slůvku
Abychom pochopili princip AI keců – vžilo se pro ně označení halucinace – musíme se trochu podívat na zoubek tomu, jak tento typ umělé inteligence funguje. Pak bude jasné, proč neexistuje jednoduchý způsob, jak by vývojáři mohli tyto halucinace „vypnout“.
ChatGPT a další chatboti používají na pozadí neuronovou síť, které se říká velký jazykový model (LLM). Obecně jsou neuronové sítě vlastně taková komplikovaná sada „vytrénovaných instinktů“. Některé neuronové sítě se trénují kupříkladu na fotkách, aby pak dokázaly rozpoznat a klasifikovat obrázky nové. Velké jazykové modely se trénovaly na velkém množství textu, a umí tak texty doplňovat.
Zřejmě máte s podobným doplňováním – řekněme s malým jazykovým modelem – osobní zkušenost. Je už řadu let běžnou součástí dotykové klávesnice na vašem mobilu. Když napíšete slovo, klávesnice vám nabízí tři další slova, která nejspíše budou následovat.
Velmi podobně sestavují texty i ChatGPT, Gemini a další chatboty postavené na LLM. Naše prediktivní klávesnice na mobilu bere při nabízení variant v potaz jen několik předchozích slov. Naproti tomu síť LLM je o několik řádů větší, náročnější na trénování… a výsledky jsou mnohem pestřejší.
Tokeny: čísla místo slov
Namísto slov pracují s tokeny, což jsou předem připravená slova nebo části slov. Neuronová sít každý text rozseká na tyto tokeny, aby s ním mohla dále pracovat.
Firmy obvykle nezveřejňují přesně, na jakém množství textů svůj model vytrénovaly, ale v podstatě lze předpokládat, že do trénovacích dat zahrnuli (k nelibosti vydavatelů) všechny texty, které na internetu našli. Odhaduje se, že šlo o bilióny slov.
Vytrénovaný instinkt místo databáze
Pak nastává výpočetně nejnáročnější fáze, která stojí miliony až stovky milionů dolarů: trénování neuronové sítě. Podobá se to tomu, když se student připravuje na test. Zakryje si část svých poznámek a snaží se vzpomenout, co tam patří. Pak se podívá, zda to odhadl správně. Pokud ano, je povzbuzen, pokud ne, musí se učit dál. Tyto poznatky pak umí uplatnit při generování textu.
Vy se ChatGPT ptáte na nějakou otázku, řekněme: Jak se anglicky řekne „Já tomu ale vůbec nerozumím!“. Rekordní počet uživatelů si ChatGPT získal právě svou intuitivní použitelností. Napíšete otázku a dostanete odpověď.
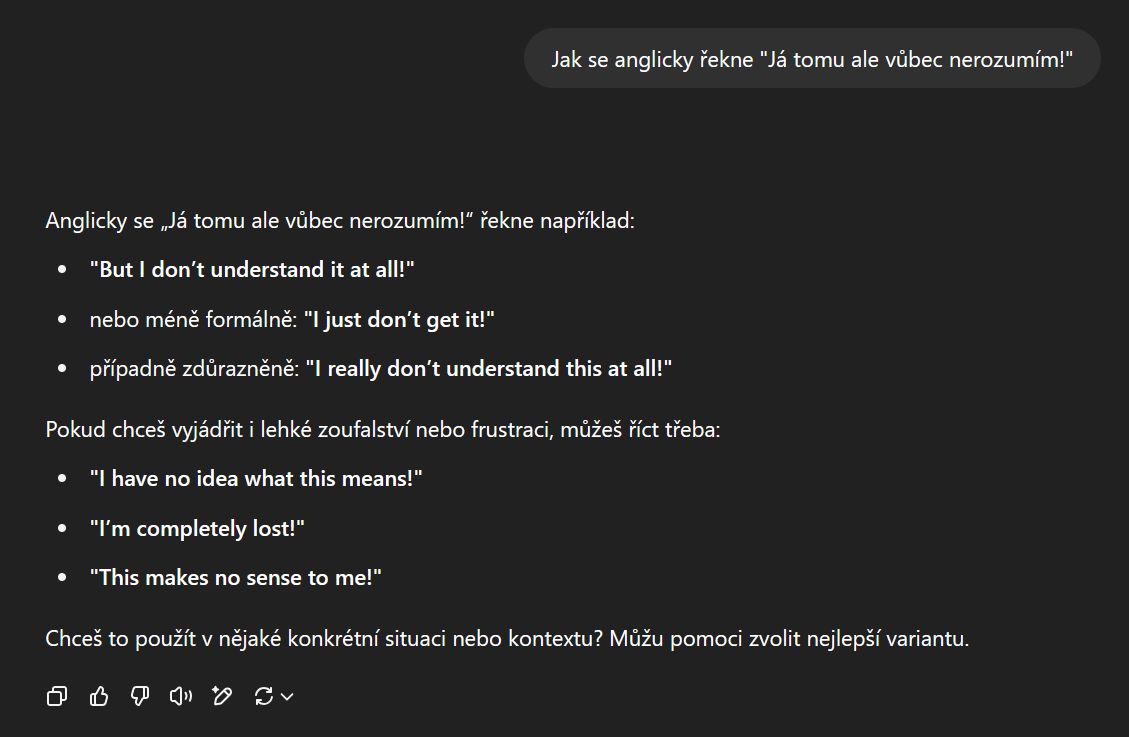
Ukázka odpovědi od ChatGPT, konkrétně modelu GPT-4o.
Model ale ve skutečnosti neodpovídá na vaši otázku. Místo toho dokončuje tento text:
Kde se ale ukrývá ta inteligence a kreativita, kterou se velké jazykové modely údajně vyznačují? Je to trochu komplikovanější otázka, ale zjednodušeně lze říci, že jde o výsledek pozornosti. Neuronová síť totiž při generování textu bere v potaz nejen poslední slovo, ale celý kontext. Tedy veškerý text, který je součástí zadání.
Vyzkoušejte si, jak se mění generovaný text na základě kontextu:
Tady je hlavní rozdíl mezi velkým jazykovým modelem a staršími počítačovými programy. Dříve počítače uměly smysluplný text generovat pouze vyhledáním v databázi nebo následováním člověkem připravené šablony. Velký jazykový model ale na stejné zadání vygeneruje pokaždé trochu jiný text.
Něco na povzbuzenou
Velký jazykový model tvoří výsledný text slovíčko po slovíčku. A pokaždé si na základě veškerého dostupného kontextu spočítá, které slovo zařadit jako následující. Toto nové slovo se tím okamžitě stává součástí zadání a celý proces se opakuje.
Pamatujete na svou prediktivní klávesnici na mobilu? Ta vám nabízí vždy tři slova, která jsou podle jejího frekvenčního slovníku nejpravděpodobnější. LLM je složitější, a tak to slovo vybírá klidně z několika desítek kandidátů. Pro každého z nich si na základě svých vytrénovaných instinktů spočítá pravděpodobnost.
Podívejte se, jak vypadají pravděpodobnosti pro jednotlivá generovaná slova:
Podle čeho ale jazykový model vybírá, kterého z kandidátů vybrat? Kdyby pokaždé zvolil nejpravděpodobnější slovo, výsledky by byly dost nudné. Pokud by naopak vybíral slova zcela náhodně, text by se okamžitě rozpadl.
Zde se dostáváme k fascinujícímu – byť běžným uživatelům zcela skrytému – parametru jazykových modelů. Přezdívá se mu teplota (temperature).
Vyzkoušejte si, jak se mění generovaný text:
V podstatě by se dala stoupající teplota LLM přirovnat k účinkům alkoholu na lidský mozek. Snižuje zábrany, snižuje dodržování norem a zvyšuje zajímavost výstupů. Pokud to ale přeženete, stane se výstup zcela nesrozumitelným.
Nastavení „teploty“ určuje, jak LLM vybírá příští slovo (token) z nabízených kandidátů. Při teplotě nula zvolí pokaždé tu nejpravděpodobnější možnost. Při tomto nastavení dá model na stejnou otázku vždy stejnou odpověď. Teplotu si uživatel může zvolit, pokud používá model pomocí volání API nebo skrze pokročilé nástroje. Běžný chatbot nenabízí změnu tohoto parametru.
Pokud vás napadlo, že posuvník s teplotou by mohl vést k odstranění halucinací, nejste sami. Nižší teplota skutečně vytvoří „nudnější“ výstupy. Ale to samo o sobě neznamená, že budou pravdivé. Vlastně to ani tak být nemůže. Neuronová síť totiž neví, co je pravda, a co ne. „Není to něco, co má znalosti o našem světě,“ připomíná výzkumník Josef Šlerka. „Jsou to spíš generátory možných světů, generátory možných textů.“
Halucinace zaskočí pitomostí i přesvědčivostí
Od svého prvního článku o ChatGPT se snažím vytrvale čtenářům připomínat, že odpovědi chatbota vypadají věrohodně, což ale neznamená, že jsou důvěryhodné. Což zároveň neznamená, že nemůžou být užitečné. Chatbot často skvěle poradí, jak řešit různé – třeba i velmi specifické – situace. Pomůže s psaním nebo vymýšlením alternativ. Naprogramuje za vás i poměrně komplikované skripty nebo krok po kroku vyřeší logické hádanky.
Zároveň je ale schopen ze sebe sypat neexistující zákony, a to včetně jejich čísla. Nebo sice použije správné číslo paragrafu, ale dá přesně opačnou odpověď, než která z něj vyplývá.
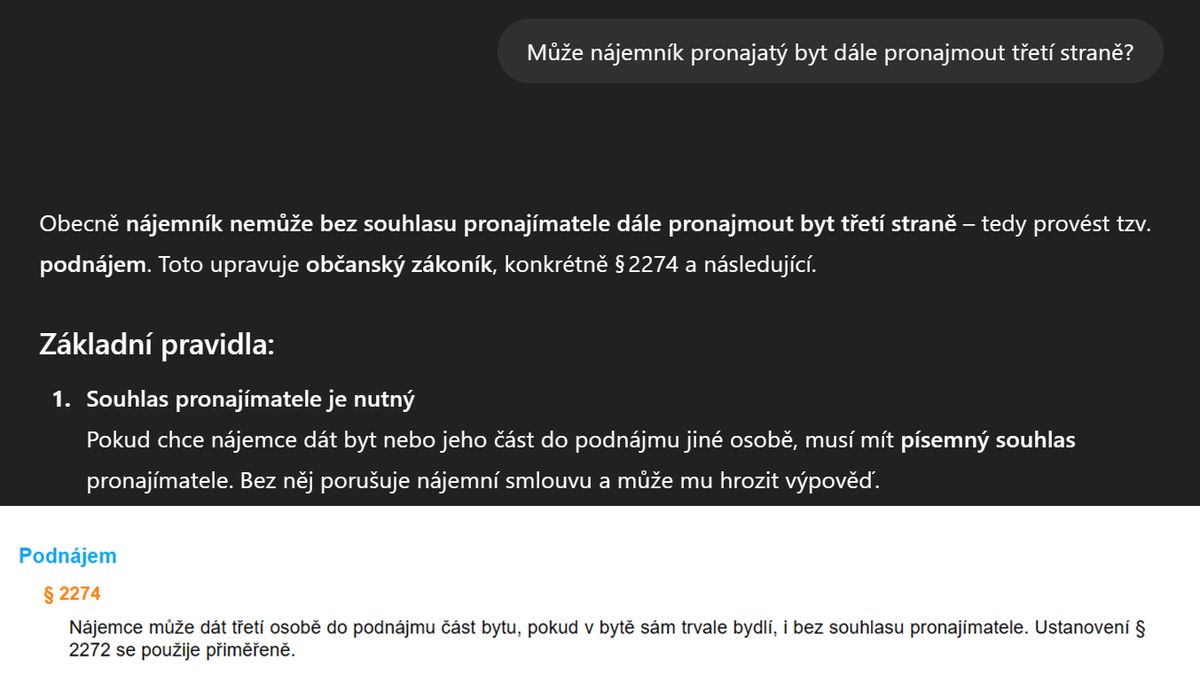
ChatGPT sice cituje paragraf § 2274 Občanského zákoníku, ale vyvozuje z něj pravý opak toho, co v zákoně stojí.
Takové sebevědomé – a věrohodně vyhlížející – zdůvodnění špatné odpovědi je pro mnohé uživatele bez nadsázky šokující. Zřejmě proto, že kdyby jim takto kecal člověk, právem to považují za nezodpovědnost, nebo rovnou za zradu vzájemné důvěry. Bavili byste se s někým, kdo vám takto bezostyšně kecá?
Některé halucinace jsou vtipnější než jiné. Třeba když mi chatbot tvrdil, že při hledání odpovědi na mou otázku se pro jistotu spojil se dvěma českými novináři.

Gemini tvrdí, že se ozval mimo jiné i Pavlu Kasíkovi. O tom bych snad něco věděl…
Chatbot se – v současné verzi – neumí s nikým spojit nebo někam volat. Stejně tak třeba neumí pracovat na nějakém úkolu na pozadí. Přesto nemá problém občas velmi sebevědomě tvrdit, že tak právě učinil. „Pomoc, ChatGPT pro mne už týden připravuje analýzu. Když se jej zeptám, kdy už to bude, tak vždycky tvrdí, že už to jen dokončuje a za chvíli bude ke stažení, co mám dělat?“ zní jedna z mnoha úpěnlivých otázek na toto téma.
Citace měly pomoci, ale…
Navzdory svým halucinacím – nebo možná právě díky nim – se ChatGPT stal nejrychleji rostoucí službou v historii a za dva měsíce od spuštění nasbíral sto milionů uživatelů. Všechny firmy začaly hledat způsob, jak snížit míru halucinací, a zvýšit tak užitečnost této revoluční technologie.
Kromě vylepšování samotných jazykových modelů (složitější struktura, více trénovacích dat, delší trénování…) přišli výzkumníci s celou řadou nápadů, jak kvalitu odpovědí vylepšit. Nejjednodušší se zdálo poskytnout modelu externí zdroj dat. Podobně, jako dostal ChatGPT kalkulačku, aby mohl spočítat příklady, dostal možnost zavolat si vyhledávač, přečíst si text ze stránek a tento text využít při psaní odpovědi.
Nápad logický, provedení více méně přímočaré… Chatbot napřed prohledá web pomocí vyhledávače, poté si přečte stránky, které vypadají relevantně, a pak tyto stránky může citovat ve svých odpovědích.
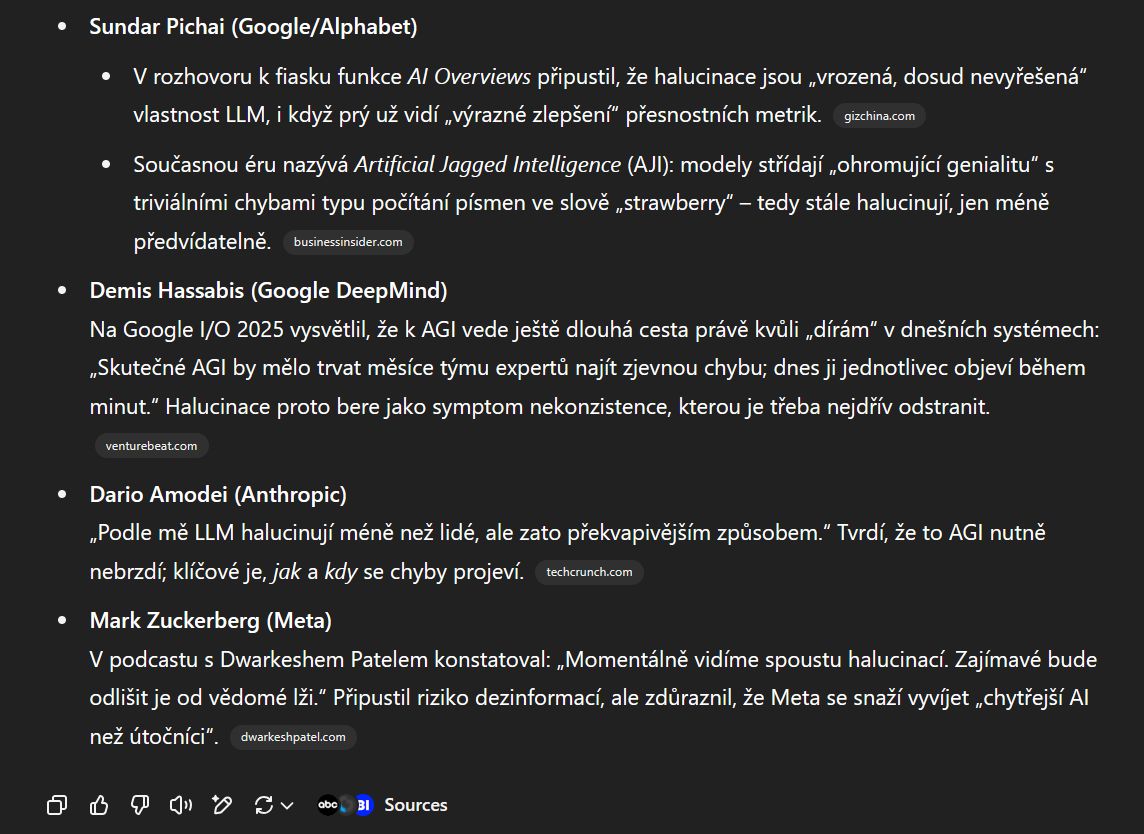
ChatGPT umí ve verzi o3 své nápady do značné míry dohledat a ověřit pomocí vyhledávače. Uživatel pak může kliknout na příslušný zdroj.
Některým halucinacím se tak určitě zabránilo. Navíc tak může chatbot dát odpovědi i na otázky týkající se aktuálního stavu věcí, což samotný jazykový model neuměl.
Ale halucinace s nástupem citací z webových stránek nezmizely docela. Naopak, některé halucinace přibyly. Ovšem nyní s odkazy, které v uživateli upevňují pocit, že vygenerovanému textu může věřit. Vždyť kdo by si dal práci s uváděním desítek citací, aniž by si dal práci s jejich posouzením?


Nedávná studie Columbia University ukázala, že chatboti pomocí vyhledaných zdrojů a citací generují velmi sebevědomé odpovědi. Ty ale nejsou vždy fakticky správné. A to výzkumníci schválně vybrali takové otázky, aby na ně bylo možné pomocí vyhledávače najít odpovědi. „Celkově chatboti dali na jednoznačné otázky nesprávné odpovědi ve více než 60 % dotazů,“ všímají si autoři. „Většina testovaných nástrojů navíc prezentovala chybné odpovědi se znepokojujícím sebevědomím…“
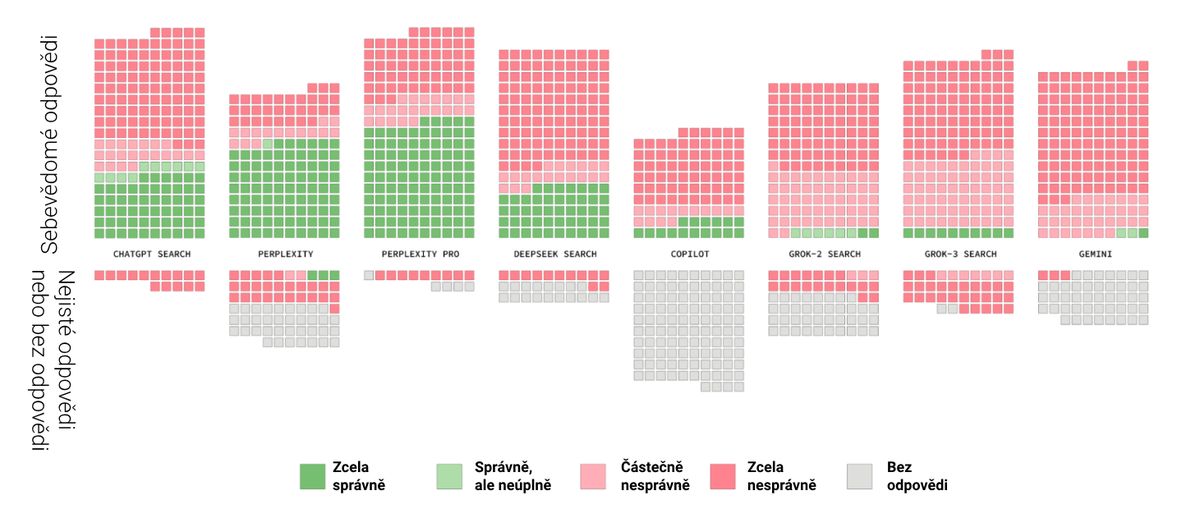
Výsledky experimentu: většina AI vyhledávačů dávala sebejisté odpovědi, které ale zdaleka ne vždy byly správné. (zdroj: CJR.org, překlad: Pavel Kasík, Seznam Zprávy)
Nejedná se samozřejmě o všeobjímající test, spíše o připomínku, že ani s vyhledávačem halucinace nezmizely.
Další naději představovaly přemýšlející modely (reasoning models). Ty umožňují chatbotovi připravit si nejprve odpověď v duchu, tedy vést jakýsi vnitřní monolog. Teprve poté chatbot generuje text odpovědi.
Na ukázce je pohled do vnitřního monologu Perplexity.
Přemýšlející chatboti se v mnohém podobají AI agentům: na základě cíle, který jim stanovíte, si umí rozmyslet postup a pracovat tak dlouho, dokud nejsou s výsledkem spokojeni. Třeba model o3 od OpenAI je pověstný svou tvrdohlavou vytrvalostí a na některých otázkách je schopný strávit vytrvalým hledáním i přes deset minut.
Dále je v nabídce ChatGPT, Gemini, Perplexity a dalších tzv. hloubkový výzkum, což je specializovaný agent, který by měl nabídnout ještě podrobnější hledání, pečlivé zvažování každého zdroje, a tím pádem i důvěryhodnější odpověď.
Výsledky hloubkového výzkumu skutečně bývají velmi dobré. Rozsahem odpovídají seminární nebo bakalářské práci vysokoškoláka a chatbot při jejich zpracování projde i stovky zdrojů. Ale zajistí to, že bude výsledný text bez halucinací? Nezajistí.
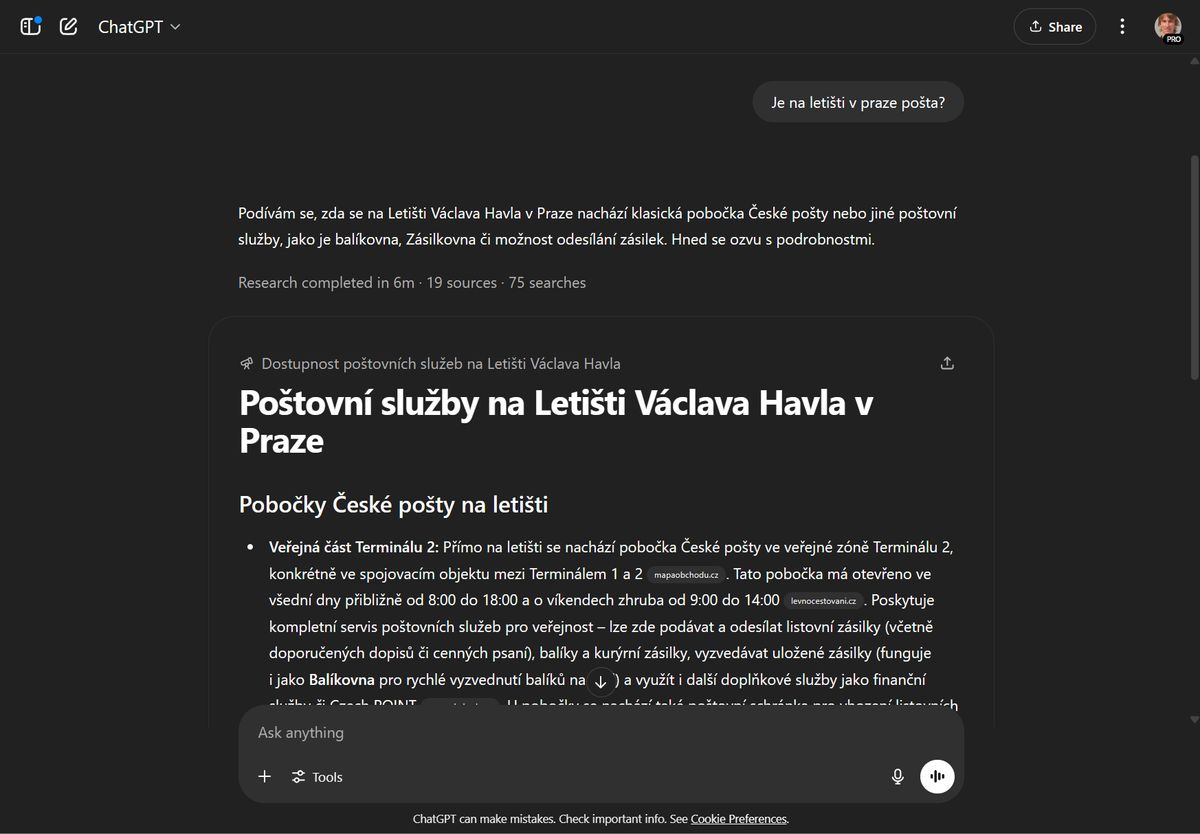
Hloubkový výzkum ChatGPT hledal šest minut, provedl 75 hledání a pročetl 19 zdrojů… a stejně dospěl ke špatné odpovědi.
Je rozhodně pravda, že v hloubkových výzkumech jsem zaznamenal výrazně méně halucinací. Když už tam ale halucinace byly, šlo o těžko odhalitelné detaily, které byly navíc do celkového dokumentu šikovně zakomponovány. Jinými slovy, halucinace jsou u chytřejších modelů méně časté, ale také hůře odhalitelné.
Nejnižší míry halucinace dosahují velké jazykové modely tam, kde jim nedáte příležitost si vymýšlet. Tedy když jim dodáte všechny potřebné informace přímo do zadání. Ale i pak si občas něco vycucají z prstu. Jen je to výrazně nižší pravděpodobnost, u pokročilých modelů se pohybuje kolem jednoho až dvou procent. Což je oproti skoro 60 % sebevědomých halucinací v testu výše rozhodně pokrok. Ale nula to pořád není.
Největší nevýhoda, nebo naopak přednost?
Na druhou stranu jsou to právě halucinace, které umožňují chatbotům tvořit nové věci, a dělají tak z umělé inteligence ideálního pomocníka pro brainstorming, vymýšlení kreativních řešení nebo hledání ne zcela evidentních souvislostí napříč obory.
Je tedy tato nevýhoda ve skutečnosti výhodou? Sam Altman, zakladatel a šéf OpenAI, v roce 2023 zdůraznil, že umělá inteligence je užitečná právě díky těmto halucinacím: „Jednou z těch neintuitivních věcí je, že velká část přidané hodnoty těchto systémů je do značné míry spojena právě s tím, že halucinují,“ poznamenal Altman. „Pokud chcete něco vyhledat v databázi, na to už máme dobré nástroje dávno.“
Při jiné příležitosti Altman poznamenal: „Nejvíce chci lidi varovat před problémem halucinací. Model vám bude sebevědomě tvrdit věci, jako kdyby to byla realita, a přitom budou úplně smyšlené. Neuvažujte o tom modelu jako o databázi faktů, spíše jako o přemýšleči.“ Podle něj by byla chyba chtít AI nástroje proměnit v databázi: „Chceme se přiblížit ke schopnosti uvažovat, ne schopnosti memorovat.“

Jazykový model neví, co je skutečné a co ne. Vše, co vytváří, je výsledkem instinktů založených na trénovacích datech. Nemá ale definitivní informace o tom, co je skutečné a co smyšlené.
Podle některých jsou právě halucinace způsob, jak se jazykové modely stávají inteligentními. „Lidé často vnímají halucinace jako chybu, kterou je nutné vymýtit,“ upozorňuje studie severoamerických lingvistů. „Ale naše průzkumy ukazují, že schopnost sémantické halucinace u umělé inteligence, podobně jako lidská fantazie, souvisí se schopností nacházet smysluplná řešení nebo lépe komunikovat.“
Pro posouzení, kde jsou halucinace přínosné a kde naopak nebezpečné, je vhodné pochopit jejich princip. Pro firmy i profesionály představují významné riziko z hlediska důvěryhodnosti. Pokud pod svým jménem prezentujete vygenerované nesmysly, pošramotíte tím pověst svou, nebo rovnou celé vaší firmy a značky.
„Jedno doporučení neexistujícího produktu, jedna chybná citace ze zákona a můžete přijít o léta budovanou reputaci,“ varuje Jim Liddle, šéf inovací v technologické firmě Nasuni. „Lidé nebudou rozlišovat, zda udělala chybu umělá inteligence, nebo vaše firma.“
Umělá inteligence spřádá texty v jistém smyslu podobně, jako náš mozek spřádá sny. Náš mozek si představuje možné i nemožné věci na základě toho, co se o světě naučil. Umělá inteligence generuje pravděpodobné texty na základě trénovacích dat.
Proto – alespoň v současné chvíli – platí doporučení: pokud potřebujete za výsledek ručit, tak nesmíte spoléhat jen na umělou inteligenci. Ta totiž často neví, co je realita a co je sen.
Poznámka: Do článku jsme doplnili podrobnější vysvětlení pojmu teplota.







