






Článek
Nástroje umělé inteligence se rychle vyvíjejí. Jsme nejspíš teprve na úplném startu nové éry a objevuje se čím dál tím víc nevyjasněných právních otázek. Jednou z nich je otázka trénování. Zjednodušeně řečeno: může se neuronová síť chovat jako člověk, číst si cizí veřejně dostupné texty a učit se z nich? Nebo robot v takovém případě pořizuje „kopii za účelem dalšího šíření“, což by bylo zřejmě protiprávní?
Čtete ukázku z newsletteru TechMIX, ve kterém Pavel Kasík a Matouš Lázňovský každou středu přinášejí hned několik komentářů a postřehů ze světa vědy a nových technologií. Pokud vás TechMIX zaujme, přihlaste se k jeho odběru!
Službě ChatGPT teoreticky hrozí, že pokud stížnosti uspějí, bude muset své vytrénované modely smazat a začít znovu. Americká stanice NPR přinesla informaci o tom, že společnost New York Times (vydavatel slavného stejnojmenného deníku) zvažuje žalobu na firmu OpenAI, která stojí za populární službou ChatGPT. Trnem v oku jsou texty článků New York Times, na kterých se velké jazykové modely GPT-3 a GPT-4 trénovaly.
Zástupci New York Times podle zdrojů NPR naznačují, že ChatGPT je vůči deníku v konkurenčním vztahu a zneužil autorským zákonem chráněný text k vlastnímu obohacení na jejich úkor. Pokud by se u soudu takový čin podařilo prokázat, nebylo by pro OpenAI vůbec jednoduché se s tím vypořádat.
Modely GPT-3 a GPT-4 jsou už totiž vytrénované. Nelze z nich – rozhodně ne nijak smysluplně – dodatečně vypreparovat a odstranit znalosti a vazby, které vznikly trénováním na textech NYT. Soudy by tak podle oslovených odborníků mohly nakázat i smazání celého modelu, který se na textech učil, a OpenAI by jej musela trénovat znovu.
ChatGPT si vymýšlí a kecá
Nástroj ChatGPT je založený na velkém jazykovém modelu (LLM). Je vytrénovaný na velkém množství textů z internetu. Umí tak, slovo po slově, generovat důvěryhodně vypadající text.
Ale to neznamená, že jde o výsledky odpovídající realitě. ChatGPT si vymýšlí, fabuluje a sebejistě vám bude tvrdit naprosté nesmysly. Není to „chyba“, vyplývá to z principu, na kterém služba funguje.

Na to je třeba pamatovat, když uvažujete o použití k něčemu jinému než pro vlastní pobavení. Veškerý výstup z nástrojů založených na LLM berte vždy maximálně jako nápad či návrh, nikoli jako bernou minci. Vygenerovaná fakta ověřujte, než je někde použijete.
V podobné situaci byla nedávno firma Amazon, která se mimosoudně dohodla, že smaže veškeré neuronové sítě vytrénované na nelegálně shromážděných záběrech z webových kamer. A dá se očekávat, že debata o tom, která data lze nebo nelze použít k trénování neuronových sítí, bude stále ostřejší.
Firma OpenAI už čelí několika dalším žalobám ohledně porušení autorských práv. Mona Awadová a Paul Tremlay v červenci podali hromadnou žalobu na OpenAI za to, že k trénování neuronových sítí využili i jejich knihy, které jsou chráněné autorským právem, přesto ale byly „nezákonně vcucnuty“ a použité k vycvičení komerčního modelu. Další žalobu podala známá komička a spisovatelka Sarah Silvermanová.
„Jedná se o otevřené, špinavé tajemství celého odvětví strojového učení,“ řekl Matthew Butterick, jeden z právníků zastupujících Silvermanovou a další autory v řízení o hromadné žalobě. „Milují knižní data a získávají je nelegálně. Chceme na tuto praxi upozornit.“
Také několik evropských vydavatelství protestuje proti tomu, že OpenAI šíří plagiáty jejich textů. „Nechceme, aby byl náš obsah nadále rabován těmito společnostmi, které vydělávají na naší produkci,“ dodal Vincent Fleury z France Medias Monde. Prozatím některá média zakázala přístup robotovi GPTBot procházení jejich webů.
Proč to vadí až teď?
Trénování jazykových modelů (tzv. LLM) probíhá už minimálně od roku 2017, kdy vývojáři z Google vytrénovali svůj první transformátor a publikovali o tom slavnou studii Attention Is All You Need (Pozornost stačí). O rok později OpenAI vytrénovala svůj první model GPT-1, kde GPT je zkratka pro Generativní Před-trénovaný Transformátor.
Oba tyto modely byly schopny celkem smysluplně dokončit větu, možná začít další, a pak už se celistvost textu obvykle nenávratně rozpadla:
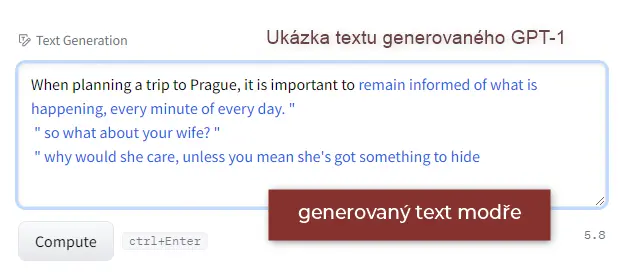
Jak fungoval model GPT-1
Tento jazykový model se trénoval na relativně malém vzorku textu, výzkumníci tehdy použili 11 000 nepublikovaných knih. Vzhledem ke schopnosti – či spíše neschopnosti – modelu GPT-1 určitě žádného z autorů a autorek netrápilo, že byl jejich text k takovému experimentu použit. Vždyť je to jen hračka.
Jenže vývojáři v OpenAI se nehodlali u GPT-1 zastavit, jak ostatně naznačoval očíslovaný název. V roce 2019 následoval GPT-2, který k trénování použil asi desetkrát větší databázi textů stažených z internetu, konkrétně textů odkázaných ze sítě Reddit.
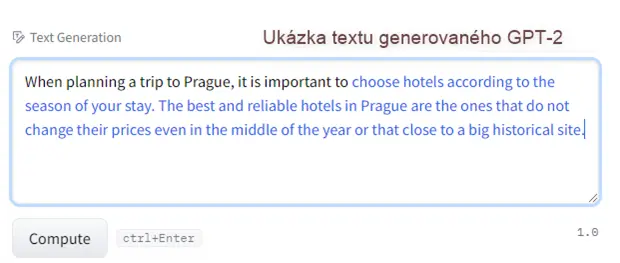
Jak fungoval model GPT-2
Je vidět, že pokrok je to výrazný. GPT-2 sice neumí řešit slovní úlohy nebo programovat, jako to zvládá GPT-4, ale pro dokončování souvislých vět a souvětí už posloužil.
Verze GPT-2 je poslední, kterou OpenAI zveřejnil jako open-source. Další verze už jsou placené, dostupné pouze uživatelům a předplatitelům. Ostatně samotná společnost OpenAI v roce 2019 změnila způsob financování. Z neziskové organizace se stala hybridní nezisko-zisková organizace se „shora omezeným ziskem“. Díky tomu OpenAI mohla začít přijímat mnohem vyšší investice, třeba miliardu dolarů od Microsoftu.
Je trénování fér?
Modely GPT-3 a GPT-4 už nejsou akademické projekty, ale naopak nástroje ke generování zisku. OpenAI zřejmě letos oslaví své nejvyšší výdělky, zatím je na cestě k ročním příjmům přibližně ve výši jedné miliardy dolarů. Je tedy logické, že se k takové firmě autoři textů staví jinak, a nelíbí se jim, že se na jejich díle obohacuje někdo jiný. Zatím ale vůbec není jisté, jak se soudy v těchto otázkách zachovají.
Určitou indikací může být rozhodnutí amerického Nejvyššího soudu z roku 2016 nezabývat se stížností autorů na firmu Google. Americký svaz autorů chtěl Googlu zabránit v tom, aby v rámci svého projektu Google Books budoval databázi knih. Texty jsou totiž chráněny autorským právem (copyright) ještě 70 let po smrti autora.
Podle soudů nižší instance (jejichž rozhodnutí se odmítnutím Nejvyššího soudu stalo konečné) je prohledávatelná databáze Google Books plně v mezích „férového použití“ (tzv. fair use). Podobně jako třeba to, že si vy jako člověk v knihovně přečtete nějakou (autorským právem chráněnou) knihu a pak vás na základě té knihy něco napadne. Nebo napíšete knihu vlastní, která bude touto knihou inspirovaná.
Co je fair use?
Americký právní koncept „fair use“ dovoluje za určitých okolností využívat díla chráněná autorskými právy (copyrightem) bez nutnosti cokoli platit nebo získávat jakékoli povolení. Cílem opatření je vyvážit zájmy držitelů práv a oprávněných společenských a individuálních zájmů, aby „autorská práva neomezovala kreativitu, kterou naopak měla podpořit“.
Fair use zaručuje možnost bezplatného užití díla například tehdy, pokud:
- jde o nekomerční nebo vzdělávací účely,
- je užita jen relativně malá část celého díla,
- jde o příklad nebo parodii s přidanou hodnotou,
- neovlivní negativně tržní hodnotu původního díla.
Jenže počítač není člověk. Klíčovou – a podle mého zatím naprosto nevyřešenou – otázkou tedy je, jak budeme fungování umělé inteligence nazývat, tedy jaká slova a metafory nakonec přijmeme za směrodatné. Přiznáme neuronovým sítím možnost se inspirovat textem, podobně jako tuto možnost mají lidé? Nebo budeme každé strojové zpracování, i zpracování skrze neuronové sítě, považovat za pořízení digitální mechanické reprodukce?
Dokázal bych asi hájit oba přístupy. Na jednu stranu chápu OpenAI, že chce ke trénování používat co největší množství co nejkvalitnějších textů, a bude argumentovat tím, že by si tyto texty mohl na internetu přečíst kdokoli a kdykoli, takže oini nedělají nic jiného. Na druhou stranu vnímám rozdíl mezi člověkem a strojem: stroj pořizuje kopii, kterou může teoreticky dále dokonale reprodukovat, což od člověka nečekáme. V případě OpenAI se pak dá říci, že tuto kopii dále „přeprodává“.
Umělá inteligence na vzestupu
Strojové učení není žádnou novinkou. Teprve v posledních letech se ale ke slovu dostaly tzv. velké jazykové modely. Nejznámější ukázkou je populární ChatGPT, jehož fungování podrobně popisujeme v tomto článku:
Důležitým faktorem aktuální popularity systému umělé inteligence je velké množství textů dostupných na internetu. A také rychlý hardware, který umožnil vytrénování řádově výkonnějších modelů. Takových, ve kterých se objevuje „emergentní chování“, jež se v některých ohledech vyrovná lidské inteligenci:

To samozřejmě vyvolává debatu o tom, zda nová vlna automatizace nahradí lidskou práci. V tomto článku shrnujeme současné poznatky a predikce ohledně toho, jak AI změní pracovní trh a kterých profesí se dotkne nejvíce:

A vracíme se k otázce: přiznáme strojům stejnou ochranu, jako lidem? Kdyby přišel člověk do veřejné knihovny, může tam zdarma celý den číst, a všechno, co se naučil, může informace vstřebat a klidně na tom vydělávat. Ale nemůže knihy z knihovny vzít, strčit do batohu, vynést je ven, okopírovat a pak je prodávat. Která z těchto dvou metafor je bližší realitě? Kterou přijmeme a kterou odmítneme?
Jinými slovy, vůbec netuším, který z těchto dvou přístupů je správný a který vyhraje. Tipl bych si ale, že se prosadí nějaký kompromis a vzniknou mechanismy, jak budou moci autoři svůj text prodat k natrénování a jak to naopak budou moci zakázat. Čekám také nějaké dodatečné mechanismy, které zabrání nejhorším excesům: falešným citacím, citacím bez atribuce nebo chybným citacím. Napřed ale obě strany nejspíš zkusí poměřit síly u soudů.
Každopádně je jasné, že tyto žaloby jsou rovněž uznáním toho, jak důležitou roli jazykové modely hrají. Před pěti lety to byly nepoužitelné hračky. Nyní se v nich budou točit miliardy.
V plné verzi newsletteru TechMIX toho najdete ještě mnohem víc. Přihlaste se k odběru a budete ho dostávat každou středu přímo do své e-mailové schránky.







