






Článek
Strojové učení, rozhodovací algoritmy a umělá inteligence. Pro hodně lidí jsou to těžko uchopitelné pojmy, které mají vzdáleně spojené s nějakou vzpourou robotů v hollywoodském trháku. Jenže algoritmy jsou ve skutečnosti všude kolem nás a strojové učení (někdy nazývané jako „umělá inteligence“) už dnes rozhoduje o všem možném.
Dávno už to nejsou jen maličkosti typu „jaký film mi Netflix doporučí“ nebo „co se mi ukáže na Facebooku“. Strojové učení má reálné dopady na naše životy.
Algoritmy využívající neuronových sítí posuzují naši žádost o úvěr, rozpoznávají náš obličej na letišti, rozhodují o odmítnutí uchazečů o práci a v USA dokonce radí, komu odpustit trest a koho nechat ve vězení. V takovém momentu skutečně záleží na tom, zda jsou tyto algoritmy férové.
Meredith Broussardová je jedna z odborníků, kteří vytrvale poukazují na problémy a zaujatost toho, čemu se dnes říká umělá inteligence.
Umělá inteligence je rafinovaná statistika
Pamatujete si, kdy jste se poprvé setkala s konceptem umělé inteligence?
Nemyslím, že si dokážu vybavit první setkání. S počítači jsem vyrůstala a programovala jsem od svých jedenácti let. Vlastně si nepamatuji, že bych někdy nepracovala s počítači. A tak mi všechny ty koncepty přijdou docela přirozené, včetně umělé inteligence.
Pojem umělá inteligence vznikl v roce 1956 na Dartmouth College, kde se setkala skupina matematiků a v podstatě definovala, čemu se bude říkat umělá inteligence. Ale od té doby se ten pojem hodně posunul. Dnes vlastně znamená více věcí. Někdo pod tím pojmem může vidět zabijácké roboty, kteří povstali proti lidem. Někdo pod „AI“ (artificial intelligence, umělá inteligence, pozn. red.) vidí strojové učení, což je v podstatě taková rafinovanější statistika. A strojové učení samozřejmě není jedinou kategorií umělé inteligence. Ty pojmy jsou vůbec zavádějící a nepomáhají lidem pochopit, o co skutečně jde.
Vnímám nicméně rozdíl mezi programem, který je naprogramován jako sekvence neměnných příkazů, a algoritmem strojového učení, který své chování výrazně mění na základě zpracovaných dat. Myslíte, že lidé rozumí tomu, jak počítače fungují?
Opravdu mi záleží na tom, aby lidé chápali, jak informatika funguje. Přijde mi, že informatici a programátoři se často chovají trochu povýšeně vůči laikům, kteří se snaží porozumět, jak věci fungují. Jde podle mého spíše o problém mezilidské komunikace než o problém technický. Chci, aby lidé rozuměli fungování počítačů. Aby věděli, co je algoritmus a co je strojové učení. A aby se tedy mohli ozvat ve chvíli, kdy se stanou obětí nějaké nespravedlnosti, která souvisí se zapojením počítačových systémů.
V dnešní době jsme celou řadu rozhodnutí delegovali na počítačové algoritmy. A tyto algoritmy nedělají nutně lepší rozhodnutí než lidé. Když pochopíte, že počítač nedělá lepší rozhodnutí jen proto, že je to počítač, a že máte právo se ozvat, když nějaký počítač rozhodl ve váš neprospěch… toto vědomí vrací lidem hlas. Vrací je do hry a dává jim kontrolu nad svým životem.

Říkáte, že lidé delegují rozhodovací procesy na počítače. Je to podle vás tím, že lidé nechtějí dělat nepohodlná rozhodnutí a pak říci, to já ne, to rozhodl počítač? Nebo chtějí lidé udělat správné rozhodnutí a na počítač se spoléhají, protože počítači věří více než svému úsudku?
Myslím, že se děje obojí. Ve své knize mluvím o myšlence technooptimismu (v originále technochauvinism), tedy tendenci některých lidí považovat technologická řešení za nadřazená těm netechnickým. Je to určitý zkreslující stereotyp. Technologičtí optimisté věří, že počítače jsou méně zaujaté, že jsou objektivnější než lidé.
Připomínám lidem, že by neměli považovat počítač za nejlepší řešení všech problémů. Místo toho bychom měli vždy přemýšlet, jaký nástroj je nejlepší pro řešení konkrétního problému. Někdy bude nejlepší řešit to skrze počítačový program, jindy bude nejlepším nástrojem kniha, jindy příběh. Jeden nástroj není automaticky lepší v každé situaci, jde o kontext.

Meredith Broussard učí datovou žurnalistiku na New York University. Studuje využití nástrojů strojového učení v žurnalistice a dlouhodobě se věnuje tématu zkreslení (biasu) v rozhodování AI.
Příkladem může být počítačový nástroj pro posuzování rizikovosti žadatelů o půjčku. Některé banky rozhodují, komu dají hypotéku a za jakých podmínek, na základě počítačové analýzy dat o daném žadateli. Takový algoritmus se obvykle vytrénuje na minulých datech a tato data pak ovlivňují budoucí výsledky. Jenže tímhle způsobem vlastně replikujete minulá rozhodnutí, a tato rozhodnutí jsou v USA protkána řadou nespravedlností a rasových nerovností. Počítač by pak bílým kandidátům dal půjčku spíše než černým kandidátům, když to zjednoduším. A to není něco, co je pro společnost žádoucí. Chceme žít ve společnosti, kde lidé nejsou diskriminováni, kde mají rovné příležitosti. Chceme, aby bylo hodnocení kandidátů založeno na jejich chování a na současné realitě, nikoli na nespravedlnostech minulosti.
Reálné příklady diskriminace počítačovým algoritmem
Nástroj pro posuzování rizika recidivity COMPAS vytváří u každého odsouzeného „rizikové skóre“. Čím vyšší, tím větší je šance, že vězeň „spáchá do dvou let od propuštění násilný čin“. Analýza ProPublica v roce 2016 ale prokázala, že skóre bylo velmi neúspěšné (strefilo se jen v pětině případů). Navíc bylo skóre výrazně vyšší u černochů. Například 18letá černoška dostala za první přestupek (krádež dětské koloběžky) rizikové skóre 8 z deseti, zatímco 41letý bílý recidivista po podobné krádeži dostal skóre 3 z deseti, přestože už byl minule usvědčen z násilné činnosti. Analýza tisíců záznamů ukázala, že jde o konzistentní trend.
Americký lékařský systém spoléhá na algoritmus, aby odhadl, kdo bude vyžadovat lékařskou péči navíc. Analýza více než 200 milionů záznamů v roce 2019 ukázala, že systém výrazně preferoval bělochy, zatímco černochům zdravotní péči navíc nedoporučoval, a to i v případech, že měli stejné zdravotní problémy. Výzkumníci upozornili dodavatele algoritmu na tento problém a podařilo se jim toto znevýhodnění téměř odstranit (snížit o 80 %). Zajímavé je, že algoritmus neměl k dispozici údaj o rase pacienta, k diskriminaci docházelo díky tomu, že systém doporučoval více péče tomu, kdo v minulosti hodně péče čerpal, a tím znevýhodňoval lidi zdravotním systémem přehlížené nebo ty, kterým často doktoři nevěří.
Americká firma Amazon používala při výběru uchazečů nástroj využívající strojového učení. V roce 2015 Amazon zjistil, že jejich nástroj diskriminoval ženy a na technické pozice častěji obsazoval muže. Nešlo jen o to, že by se na tyto pozice muži častěji hlásili nebo že byli schopnější. Pokud se ucházeli stejně zkušení kandidáti, algoritmus vybral muže a odfiltroval ženu. Algoritmus přímo penalizoval „dívčí“ aktivity v životopisu, a ani pokus tento algoritmus upravit nebyl úspěšný.
Slavným případem je žádost o půjčku. Když americký vynálezce Steve Wozniak, zakladatel společnosti Apple, zkusmo zažádal o půjčku u nové finanční služby Apple Card, systém mu nabídl desetkrát vyšší půjčku, než jeho manželce. „Přitom máme stejný majetek, vše je psáno na oba z nás, nemám žádné oddělené účty,“ dodal Wozniak. Vyšetřovatelé ovšem došli k závěru, že v tomto případě se o diskriminaci nejedná: „Společné jmění manželů není zárukou toho, že oba manželé dostanou stejné podmínky půjčky. Je v pořádku, aby banka brala v úvahu i další faktory, jako historii splácení.“ Vyšetřovatelé ovšem kritizovali banku, že lépe klientům nevysvětlila, jak její systém funguje.
V roce 2018 publikovala Joy Buolamwini z MIT studii, ve které ukázala, že všechny hlavní systémy pro rozpoznávání obličejů jsou výrazně méně úspěšné u lidí tmavé pleti. U černých žen bylo procento chyb až 46,8%, tedy v podstatě na úrovni náhody. „Důležité je, že tento problém se pak promítá do dalších uplatnění těchto technologií,“ zdůraznila Buolamwini. „Mohli by si dovolit takový systém prodávat, kdyby byla takováto vysoká chybovost evidentní napříč populací?“ Její studie odstartovala nejen několik občanských projektů pro zvýšení počítačové gramotnosti, ale také odezvu velkých technologických firem: IBM pozastavila licencování svého systému, Amazon dočasně zakázal jeho používání v policií a Microsoft pozastavil prodeje vládním agenturám a lokálním policejním složkám.
Myslíte, že je takový algoritmus, který replikuje minulé nespravedlnosti, výsledkem nepozornosti?
Určitě jsou lidé, kteří mají zájem na zachování stávajícího pořádku. A často jsou to lidé, kteří mají možnost věci ovlivňovat. Ale tady hraje velkou roli, co si lidé myslí o počítačích, jak je vnímají.
Pokud si někdo myslí, že strojové učení je jakási magie, nebo pokud vnímají umělou inteligenci jako něco hollywoodského… pak budou lidé mylně věřit v neomylnost strojového rozhodnutí. Budou více věřit počítači než svému úsudku. Jiný projev tohoto přesvědčení je víra v neomylnost matematiky. Ale slepá aplikace matematiky nemusí být férová z hlediska společnosti. Měli bychom vědět, jaká rozhodnutí děláme, proč je děláme a jak tato rozhodnutí zapadají do naší vize světa.
Algoritmus může diskriminovat
Kde je podle vás evidentní, že se strojové učení používá špatně a proti zájmům lidí? Něco, co si lidé umí představit?
Dobře je to vidět na příkladu rozpoznávání obličejů. Protože je tato technologie (facial recognition) většinou trénována na vzorku obličejů, kde převažují muži a běloši, tak má pak takto natrénovaný algoritmus problém rozpoznávat správně lidi tmavé pleti. Když pak tuto technologii používá policie, stává se, že na základě počítačového rozpoznání zatkne nesprávného člověka.
Na toto upozorňuje počítačová expertka Joy Buolamwiniová ve filmu Coded Bias. Myslím, že to úplně novým způsobem ukázalo tu nespravedlnost, tu „rasovou diskriminaci“ skrytou v technologii rozpoznávání obličeje.
Joy ukazuje, že rozpoznávání obličeje je disproporčně trénované na bílých obličejích, a proto špatně funguje. A někdo by mohl říct, dobře, tak prostě jen napravíme ten problém. Zahrneme do vzorku více lidí z různých etnických skupin a bude to fungovat lépe. Ale Joy jde dál a říká, ne, to nestačí. Podle ní je totiž ta technologie disproporčně používána proti dlouhodobě diskriminovaným lidem a umožňuje tak pokračovat v té diskriminaci. Řešení podle ní je: prostě nepoužívejte rozpoznávání obličeje pro zatýkání lidí.
Města a státy po celé Americe na to reagovaly, mnohde už policie nesmí používat automatizované rozpoznávání obličejů. Velké technologické firmy pozastavily vývoj policejních aplikací rozpoznávání obličejů. Také EU ve svých nových návrzích počítá s regulováním využití AI při rozpoznávání obličejů.
Se strojovým učením se ale lidé setkávají na každém kroku. Myslíte, že si to vůbec uvědomujeme?
Strojové učení se různými způsoby používá, no, řekněme, že ve většině dnešního softwaru. Když vyhledáváte na Googlu, využívá algoritmus stovky prvků strojového učení. Umělá inteligence a strojové učení vybírají, co se ukáže nahoře ve vašem newsfeedu, když si pustíte Facebook. V podstatě všechny nástroje, které vám něco doporučují, používají strojové učení.
Ale pamatujme si, strojové učení, to je matematika. Je to mnohem všednější, než si lidé představují na základě hollywoodských filmů. Není vůbec jednoduché pochopit, jak strojové učení a AI fungují, ale řekla bych, že je v možnostech každého těm základům porozumět.
Co je neuronová síť?
– Neuronová síť je typ počítačového programu, který klasifikuje nová data na základě předchozích dat.
– Výjimečné je na něm oproti klasickým programům to, že programátor nepíše, jakým způsobem se počítač rozhoduje. Počítač se analýzou dat postupně učí klasifikovat vstupní data. Využívá k tomu například neuronové sítě, což je vlastně velké množství jednoduchých programů navázaných na sebe, které pracují souběžně.
– Neuronová síť se obvykle trénuje na velké sadě různých vstupních dat, u kterých zná správnou odpověď. Umí na základě naučených vzorců klasifikovat i zcela neznámá vstupní data podobného typu.
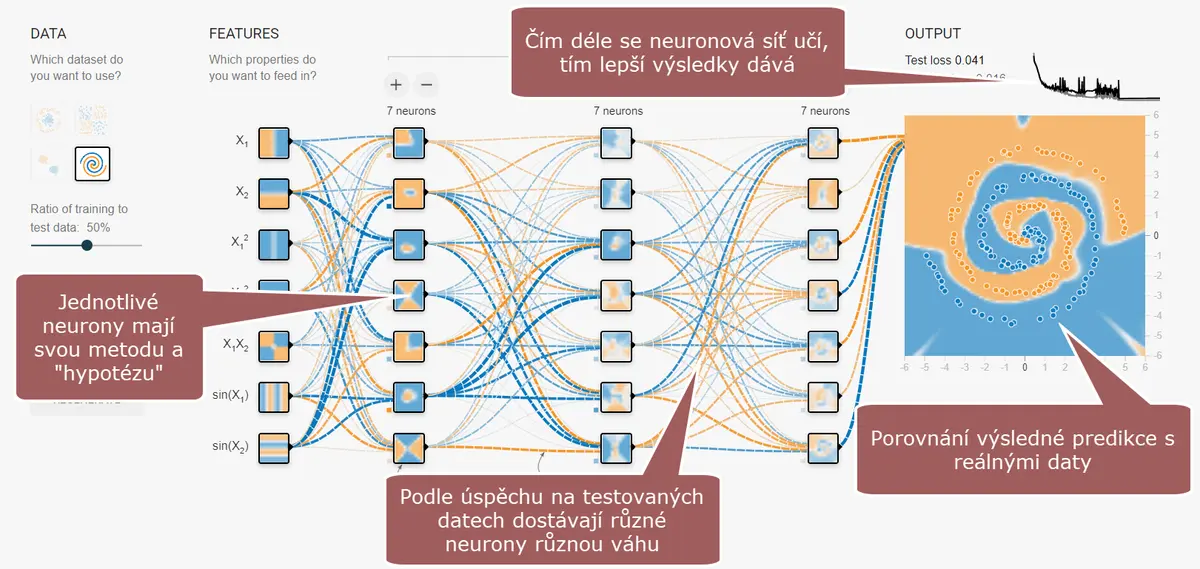
Ukázka jednoduché neuronové sítě, která se na zdrojových datech učí odhadovat, kde budou na plátně modré a kde oranžové tečky. Čím více má pokusů, tím lépe síť postupně nastaví důraz kladený na jednotlivé „neurony“ a dosahuje tak přesnějších predikcí.
Strojové učení není něco, co lze pochopit na jedno posezení. Člověk se na to musí zaměřit, musí si to vyhledat a vyzkoušet. Ale takových věcí je více, a tak víme, že se nám to vyplatí. A je k dispozici velké množství dobrých nástrojů, pomocí kterých můžete strojové učení lépe pochopit. Třeba moje kniha Artificial Unintelligence.
Ne každý ale bude poctivě studovat, aby se o AI dozvěděl více. Je něco, co by podle vás měl vědět úplně každý?
Strojové učení, to je matematika. Strojové učení má spoustu různých odvětví (deep learning, neuronové sítě, expertní systémy, zpracování přirozeného jazyka…). Ačkoli strojové učení zní jako něco z hollywoodského filmu, je to jen matematika. Umělá inteligence, to je matematika.
V něčem to je ale přeci jen odlišné. Vývojáři algoritmů založených na strojovém učení se v něčem podobají spíše pedagogům. Ladí neuronovou síť, předkládají jí data a pak ji testují, zda se něco užitečného naučila. To přece je něco nového, ne?
Lidé rádi počítačům připisují lidské vlastnosti, říká se tomu antropomorfizace. Děláme to i s mazlíčky, představujeme si, že nám náš pes rozumí a má lidské vlastnosti, je to přirozené. Ale je to zavádějící. Můžeme předstírat, že počítač je osoba, která se učí. Ale ve skutečnosti se počítač neučí, ne v tom smyslu, jako se učí lidé. Počítač nemá pocity, a když mu řeknete, že nemá pocity, tak to jeho city nezraní, protože žádné nemá.
Počítače nejsou zárukou objektivity
Kromě toho, že programujete, jste novinářka a učíte novináře, jak pracovat s daty a strojovým učením. Jakým způsobem zasahuje AI do novinařiny nyní a jak tomu podle vás bude za pár let?
Někdy si lidé představují, že musí umět programovat, aby mohli využít nástrojů umělé inteligence. Tak to ale vůbec není. Když novinář použije nástroj na automatický přepis nahrávky, využívá AI technologií. Strojové učení je všude kolem nás. Specifické způsoby využití v novinařině zahrnují třeba automatické generování textu, hodně se mluví o GPT-3. Ale už předtím to dělaly firmy jako Bloomberg nebo Washington Post, na základě předem připravených šablon generují texty o obchodních výsledcích firem nebo o sportu.
Zajímavé je využití strojového učení k analýze velkého množství dat nebo dokumentů. Třeba když se novináři dostanou k statisícům stránek uniklých dokumentů, není v silách žádného člověka, aby to vše během několika hodin přečetl nebo dokonce pochopil. Lze ale využít nástrojů strojového učení, který umí dokumenty zorganizovat, najít významné nebo nějak zajímavé pasáže a souvislosti.

Lidé někdy považují počítače nebo data za záruku objektivity. Ale uplynulý rok snad již definitivně ukázal, že nestačí mít jen data, je potřeba znát, jakým způsobem vznikla a co znamenají. Co učíte studenty, aby se této pasti vyhnuli?
Samotná data nestačí. Učím své žáky jak klasické reportážní práci, tak práci s velkým množstvím dat. Učím je, jak zkombinovat příběhy s grafy a daty. Data jsou jen jeden z nástrojů, který můžete použít k dosažení cíle.
Někdy si lidé myslí, že novinařina může být objektivní. Že jsou to jen fakta, nebo že to mají být jen strohá fakta. A že to mohou zajistit data. Možná si také někdo představuje, že nějaký generativní algoritmus schopný psát text nakonec lidské novináře zcela nahradí. Tyto myšlenky ale považuji za další projev techno-nadřazenosti.
Naše zkušenosti z webu ukazují, že lidé si opravdu váží profesionálního psaného textu. Jistě, mediální průmysl je v krizi. Ale novinařina, zkoumání reality, vyprávění příběhů, to jsou věci, které jsou stejně důležité jako dříve.
Mluvíte často o algoritmické spravedlnosti. Někdo by si pod tím termínem mohl představit, že jste zastánkyně spravedlnosti, kterou zajistí neúplatné, objektivní algoritmy. Ale vy to myslíte právě naopak. Mohla byste čtenářům přiblížit, v čem spočívá nebezpečí algoritmů v rozhodování?
Není to úplně jednoduché na porozumění. Je třeba pochopit, co je algoritmus, jak funguje, jakým způsobem je využíván a pak teprve můžete nahlédnout, čím algoritmy mohou upevňovat nespravedlnost a vést k diskriminaci.
Algoritmus je sada instrukcí, které dostanou nějaké ingredience a nějak je zpracují. Trochu jako recept v kuchařce.
Ve chvíli, kdy má algoritmus za cíl určit něco, co se dotýká lidských životů, třeba kdo bude přijat na vysokou školu, kdo dostane práci, komu banka dá půjčku… není vůbec dané, že algoritmus v takovém případě dělá lepší práci než člověk. Lidé mají dojem, že počítače jsou objektivnější než lidé, ale to je iluze. Není to zkrátka pravda.
Rozhodovací algoritmus, který funguje na principu strojového učení, vychází z dat o tom, co už se stalo, vytvoří si model skutečnosti a na základě něj dělá závěry a doporučení o dosud nezpracovaných datech.
V podstatě tedy počítači říkáte: podívej, takovýto je svět a já chci, abys to replikoval. Takže pokud je nyní ve světě nespravedlnost, nerovnost, diskriminace, sexismus, rasismus, tak všechny tyto věci pak budou i v těch datech o reálném světě. Tím pádem se dostanou i do těch modelů, které si počítač vytvoří. Algoritmus vlastně zakonzervuje existující problémy a nespravedlnosti a skryje je takovým způsobem, že je prakticky nemožné je změnit.





